|
| 1 | +# DPDK源码学习之 LPM路由匹配算法 |
| 2 | + |
| 3 | +## 1. 初衷 |
| 4 | + |
| 5 | +我学习dpdk的初衷非常简单,长期的目标是学习DPDK的优化原理,并在此基础上对现有的工作代码进行优化;短期目标是为了面试,因为实在是问的太多了,而我也仅仅是看了《深入浅出DPDK》这本书的前几个章节,基本上面试官深入询问,便不知道所以然。 |
| 6 | + |
| 7 | +面试官还经常问另一个问题:**DPDK源码你看过多少?** |
| 8 | + |
| 9 | +既然如此,那我就**裸辞在家**,开始撸DPDK源码。并将学习笔记整理出来,供大家一起讨论学习。 早些时候,只看过DPDK中的无锁队列,在实现上确实很优秀,通过学习无锁队列,真正意义上接触到了缓存一致性、内存屏障等非常重要的概念。之后在阅读代码中,发现很多地方都用到了内存屏障,例如Linux内核中的RCU机制实现特别内存屏障。**可以说内存屏障在内核态|多核并发中非常重要,鉴于此更加坚信,DPDK代码非常有必要进行仔细阅读**。毕竟可以涨姿势呀! 这里先从DPDK中的路由算法开始:**LPM** **路由匹配算法。** |
| 10 | + |
| 11 | +## 2. LPM设计原理概要 |
| 12 | + |
| 13 | +路由可以说是整个互联网的核心和基础。对于网络设备,路由模块一般是一个比较大的功能,它也是影响转发效率的关键因素。关于路由表查找算法,曾经看到一篇非常详细的文章:[Internet路由之路由表查找算法概述-哈希/LC-Trie树/256-way-mtrie树](https://link.juejin.cn/?target=https%3A%2F%2Fblog.csdn.net%2Fdog250%2Farticle%2Fdetails%2F6596046) |
| 14 | + |
| 15 | +**在** **DPDK** **中,实现了两种路由匹配算法:** |
| 16 | + |
| 17 | +- **精确匹配** |
| 18 | +- **最长前缀匹配** **(LPM)** |
| 19 | + |
| 20 | + **本文主要介绍最长前缀匹配**。 DPDK中的LPM实现综合考虑了时间和空间问题,做了一个比较好的折中,将32位的地址空间分为两部分: |
| 21 | + |
| 22 | +- 高24位 |
| 23 | +- 低8位 |
| 24 | + |
| 25 | + 这是专门针对路由表查询设计的数据结构。通过这种方式,**将IP地址空间分为二级表的方式进行查询。** 前缀的24位共有2^24个条目(16x1024x1024个),也就是说IP地址的前三个字节对应的数值在表中存在一一对应项。低8位的256个条目可以根据需求进行分配,这样可以极大的节省空间。 |
| 26 | + |
| 27 | +经过有关部门的统计分析,**当查找的** **IP** **掩码长度绝大多数是小于等于** **24** **位的,因此这部分可以通过一次内存访问便可以找到对应的路由;当查找的** **IP** **掩码长度超过** **24** **时,需要两次访问内存,而这种情况相对较少**。因 |
| 28 | + |
| 29 | +DPDK实现的LPM算法兼顾了时间和空间效率。 |
| 30 | + |
| 31 | +## 3. LPM路由查找算法 |
| 32 | + |
| 33 | +### 3.1 LPM相关的数据结构 |
| 34 | + |
| 35 | +LPM主要的结构体为: |
| 36 | + |
| 37 | +- **一张有** **2^24** **条目的一级表,称之为** **tbl24** |
| 38 | +- **多张** **(DPDK** **源码中为** **256** **张** **)** **有** **2^8** **条目的二级表,称之为** **tbl24** |
| 39 | + |
| 40 | +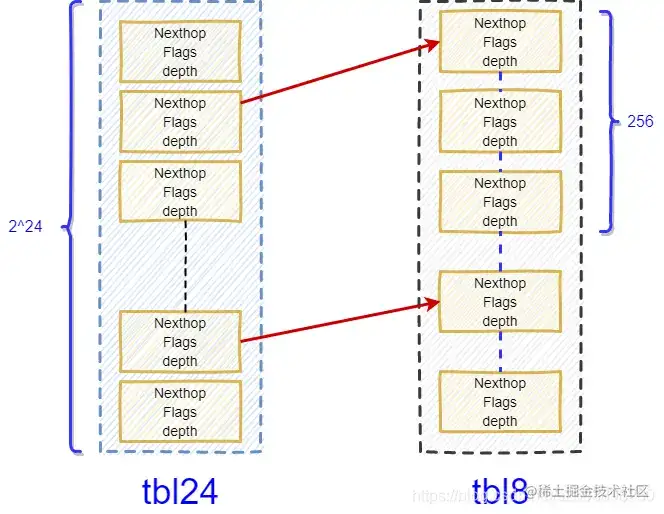 |
| 41 | + |
| 42 | +#### 3.1.1 tbl24 |
| 43 | + |
| 44 | +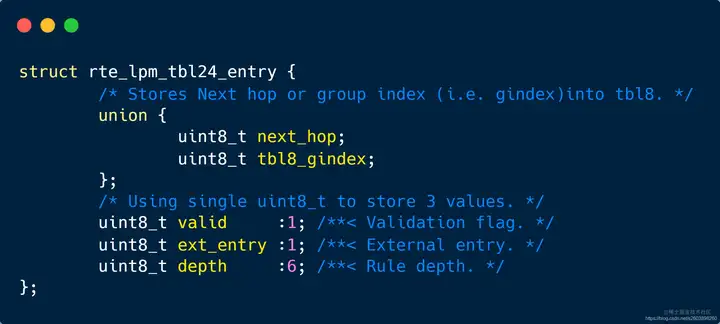 |
| 45 | + |
| 46 | +| | | |
| 47 | +| --------- | ---------------------------------------- | |
| 48 | +| 参数 | 说明 | |
| 49 | +| next_hop | 这个作为下一跳着实有点特殊,只有一个字节 | |
| 50 | +| valid | 当前一级表tbl24表项是否生效 | |
| 51 | +| ext_entry | 是否存在二级表tbl8 | |
| 52 | +| depth | 规则深度,实际上为掩码长度 | |
| 53 | + |
| 54 | +#### 3.1.2 tbl8数据结构 |
| 55 | + |
| 56 | +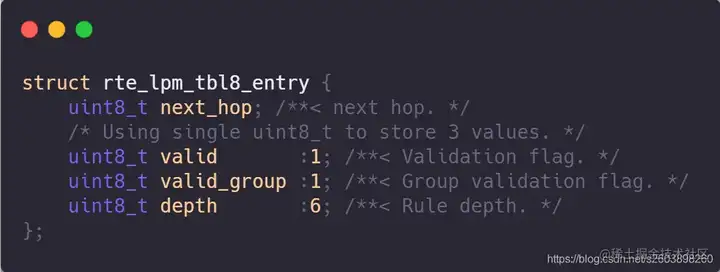 |
| 57 | + |
| 58 | +| | | |
| 59 | +| ----------- | ---------------------------------------- | |
| 60 | +| 参数 | 说明 | |
| 61 | +| next_hop | 这个作为下一跳着实有点特殊,只有一个字节 | |
| 62 | +| valid | 当前tbl8条目是否生效 | |
| 63 | +| valid_group | 有效组标记 | |
| 64 | +| depth | 规则深度,实际上为掩码长度 | |
| 65 | + |
| 66 | +#### 3.1.3 LPM数据结构 |
| 67 | + |
| 68 | +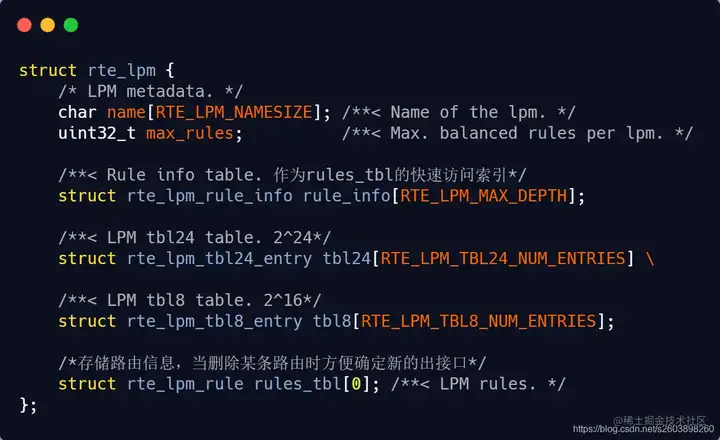 |
| 69 | + |
| 70 | +#### 3.1.4 数据结构之间 |
| 71 | + |
| 72 | +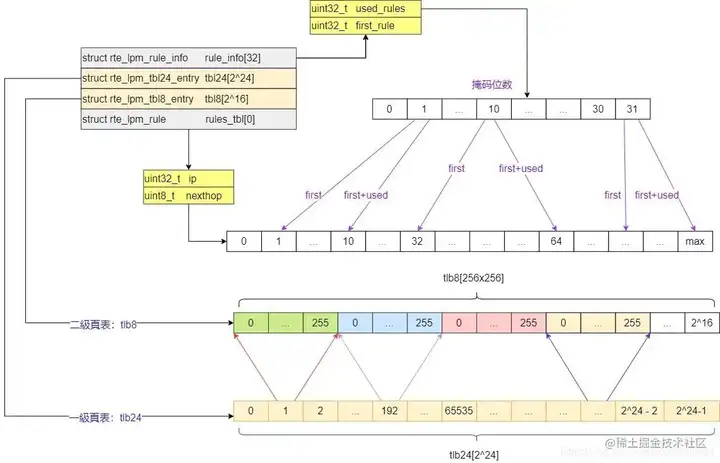 |
| 73 | + |
| 74 | +特别说明: **为了提高访问速度,采用了顺序存储**, 可以直接通过下标和偏移进行快速访问,而使用链表涉及到通过引用访问。除此之外呢,还有一个特别重要的点:**使用链表导致cache miss概率大大提高,因此CPU无法预测下一个节点的位置也就无法预加载到cache中,从而导致更多的cache miss的发生。而采用顺序存储,有很好的空间局部性,性能应该有较大的提高**。 |
| 75 | + |
| 76 | +### 3.2 LPM结构的创建 |
| 77 | + |
| 78 | +LPM路由表的创建是通过rte_lpm_create()函数实现的。而LPM的核心数据结构为struct rte_lpm, 因此LPM的创建主要对创建rte_lpm对应的对象。**其中为了灵活配置路由规模,采用传参的方式动态分配LPM路由表(这用到了0长度数组)** 。申请的**LPM** **是一个连续内存,而非常见的链式存储。** 这个比较特殊,优点嘛,就是快。 它的原理很简单: **根据传递的参数来确定支持的规则数,并在此基础上分配LPM空间。** 代码实现如下: |
| 79 | + |
| 80 | +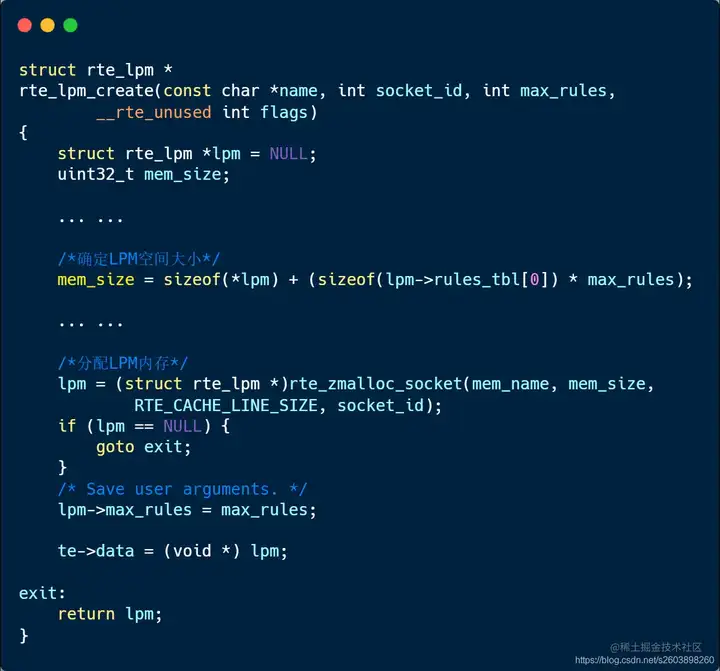 |
| 81 | + |
| 82 | +#### 3.2 LPM 添加路由 |
| 83 | + |
| 84 | +路由表项的添加是在rte_lpm_add函数中完成的。 |
| 85 | + |
| 86 | +- 首先需要获取目的网段所在的网络地址: |
| 87 | + |
| 88 | + |
| 89 | + |
| 90 | +- 将路由条目添加到rule表中,供路由表的维护、查找使用 |
| 91 | + |
| 92 | + |
| 93 | + |
| 94 | +- 根据掩码的长度确定操作的表对象,如果<=24,则使用add_depth_small添加;如果>24则使用add_depth_big添加。 |
| 95 | + |
| 96 | +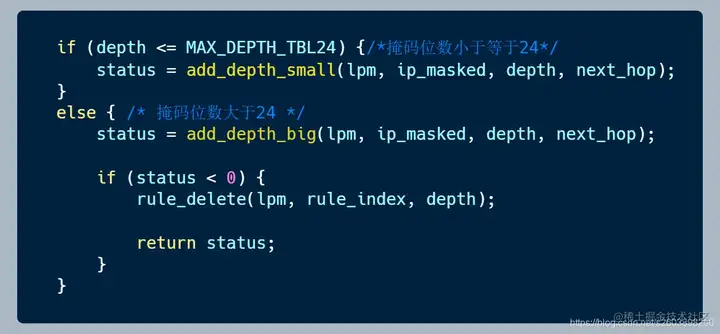 |
| 97 | + |
| 98 | + 下面分别介绍这涉及到的关键函数接口。 在LPM中,**rule是在按照掩码位数来组织的**:IPv4的掩码位数范围:0-31, 每一个长度的掩码下有可能存在多条路由。 在路由匹配算法中采用最长前缀匹配,因此最初的遍历方式如下: |
| 99 | + |
| 100 | +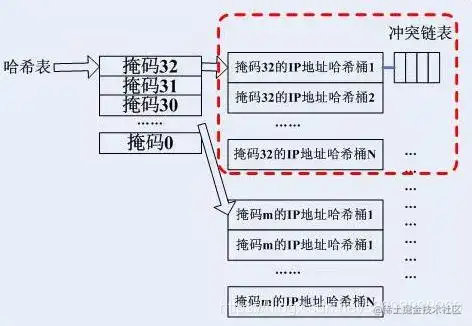 |
| 101 | + |
| 102 | + |
| 103 | + |
| 104 | +DPDK也采用了类似结构,只是是通过顺序存储实现的,而很多其他算法是通过链式存储实现的。 |
| 105 | + |
| 106 | +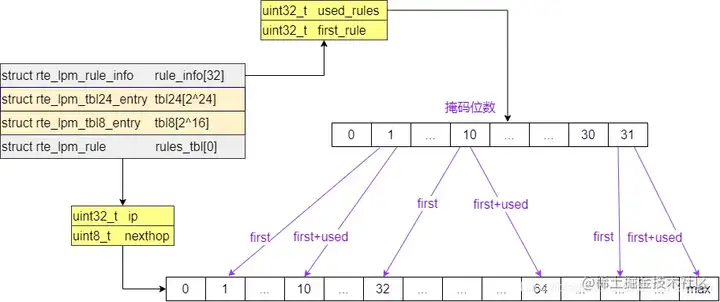 |
| 107 | + |
| 108 | +比如说掩码长度为24时的路由有多条: |
| 109 | + |
| 110 | +| | | | |
| 111 | +| ------------ | ---- | ----------- | |
| 112 | +| 目的IP | 掩码 | 下一跳 | |
| 113 | +| 192.168.10.0 | 24 | 192.168.1.1 | |
| 114 | +| 10.28.1.2 | 24 | 192.168.2.1 | |
| 115 | +| 192.168.20.0 | 24 | 192.168.2.1 | |
| 116 | + |
| 117 | + 这部分条目是存储在rules_tbl中的,每一个掩码长度对应的区间,通过(begin, begin+used)来标记空间范围。该rules结构主要是为了方便维护tbl24+tbl8二级表,当路由删除时,需要重新确定下一跳,通过rules结构可以比较优雅的找到。 |
| 118 | + |
| 119 | +**rules** **结构是** **LPM** **一个较为高级的数据结构,它的目的主要是:** **方便路由表的增删改,尤其在删除某一条路由时需要根据最长前缀匹配原则重新确定下一跳** **。** rule的数据结构可参考上图,由于是顺序存储,优点是查找效率高,但是不方便扩展,增删元素都需要移动后续元素。这也是rule代码实现中比较重要的部分,但是rule中并未移动所有后续元素,而是每一个掩码组只移动第一个和最后一个,大大减少了内存的拷贝。 基于此前提再阅读rule的实现会比较简单。 |
| 120 | + |
| 121 | +#### 3.2.1 rule_add |
| 122 | + |
| 123 | +此函数接口用来添加路由规则,路由规则实际上就是IP和掩码组成的结构。在网络层中,有两个重要的表(日常统称为路由表,并未细分):**FIB和RIB**。其中RIB为路由路由信息表,包含网络的拓扑信息,而FIB表则是RIB中最佳的路由构成的表,转发报文时使用FIB表。在DPDK的LPM中,rule表和tbl24/tbl8的关系有点类似于RIB和FIB的关系。 |
| 124 | + |
| 125 | +- **rule表: 用来维护所有的路由信息** |
| 126 | +- **tbl24+tlb8二级表: 最佳路由构成的表** |
| 127 | + |
| 128 | + **规则是按掩码长度划分的:** **下面开始介绍rule_add流程:** |
| 129 | + |
| 130 | +- **首先需要判断是否存在达到该子网的路由**,如果存在,则只需要更新rule表的nexthop即可。如果不存在则需要找到插入位置,后续分配空间插入路由信息 时使用。 |
| 131 | + |
| 132 | +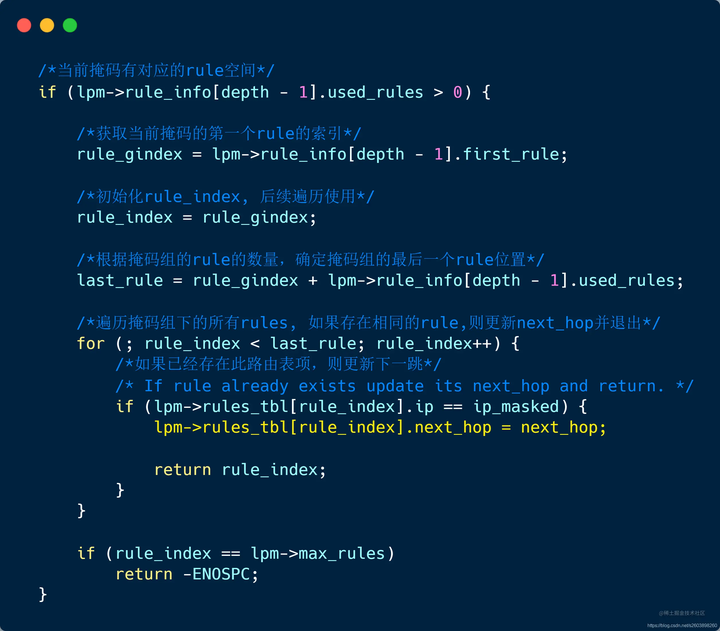 |
| 133 | + |
| 134 | +- **如果该掩码下没有rule组(如下图中的掩码2)** ,此时需要根据前一个掩码位置来计算(图中根据掩码1所占用的rule空间来计算得到) |
| 135 | + |
| 136 | +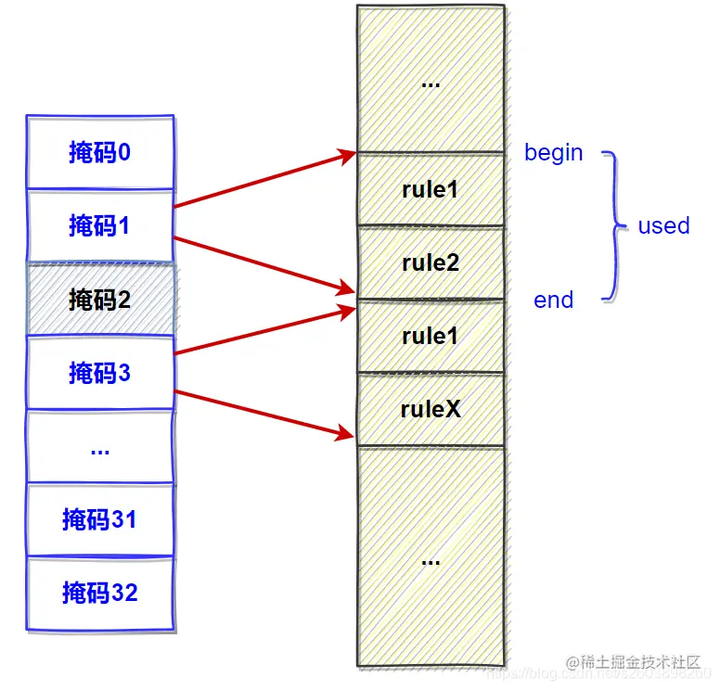 |
| 137 | + |
| 138 | +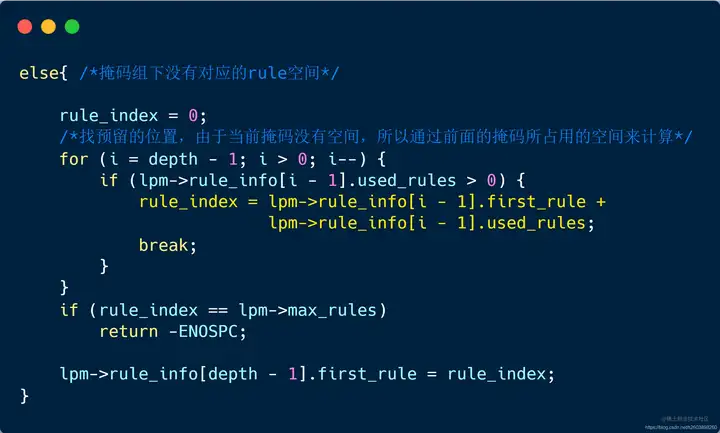 |
| 139 | + |
| 140 | +- **前方已经找到的插入位置,这里是真正需要开辟空间添加rule的地方** |
| 141 | + |
| 142 | + **由于所有的rule全部存储在一个大数组里(rules+_bl数组), 如果插入元素/删除元素需要移动后续元素**。 缺点是插入删除开销大,需要频繁移动元素;优点就快,效率高。 插入元素时,并非将所有后续元素都后移一位,而是每组移动一个(每组第一个移到下一组第一个位置),这样就可以减少内存拷贝的开销。 |
| 143 | + |
| 144 | +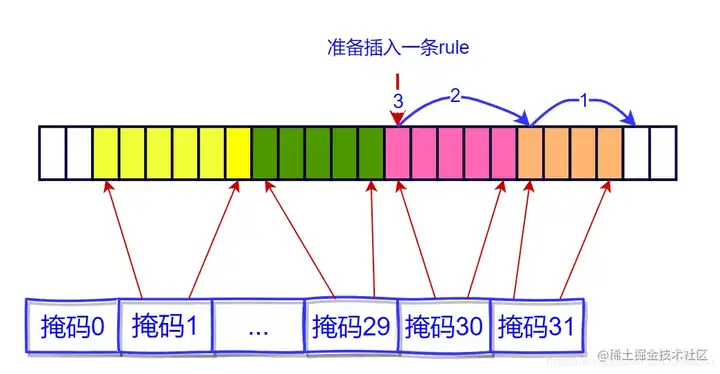 |
| 145 | + |
| 146 | +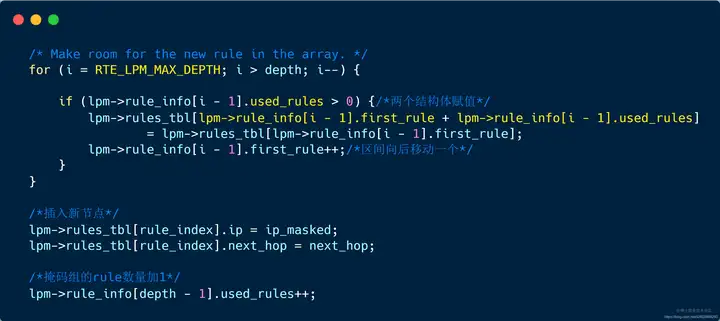 |
| 147 | + |
| 148 | +#### 3.2.2 rule_delete 在rule_add中已经知道rule的组织结构,因此删除时,最主要的工作在于:**将后续元素向前移动1个空间**。这里也是:将每掩码组的最后一个移动到前一掩码组的最后一个。这样便完成了元素的删除,同时无需进行大量数据的拷贝工作。 |
| 149 | + |
| 150 | +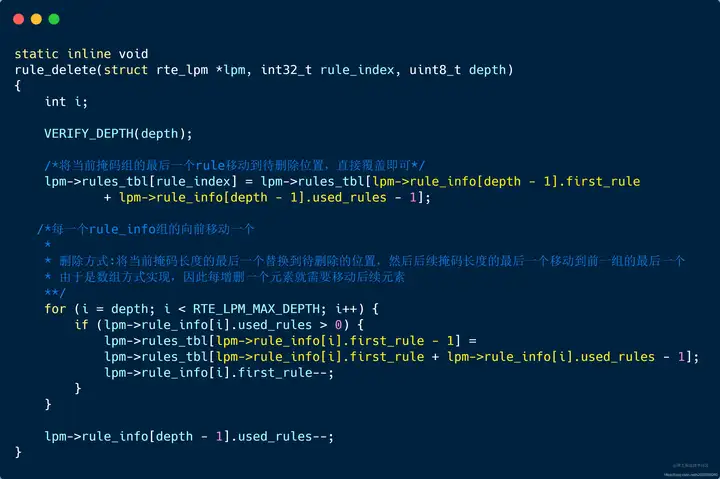 |
| 151 | + |
| 152 | +#### 3.2.3 tbl8_alloc rule组两个重要函数已经说明完毕,后面便需要介绍lpm中的tbl相关的两个重要函数: |
| 153 | + |
| 154 | +通过前面的描述,已经知道DPDK中,LPM查找匹配算法将IP分为两部分,分别对应tbl24, tbl8。当添加路由时,如果掩码长度小于等于24,则使用add_depth_small添加路由;当掩码长度大于24时,使用add_depth_big添加路由。**这里先介绍下tbl8的申请函数** |
| 155 | + |
| 156 | +**此接口用来从连续的内存中申请一个tbl8表空间。** |
| 157 | + |
| 158 | +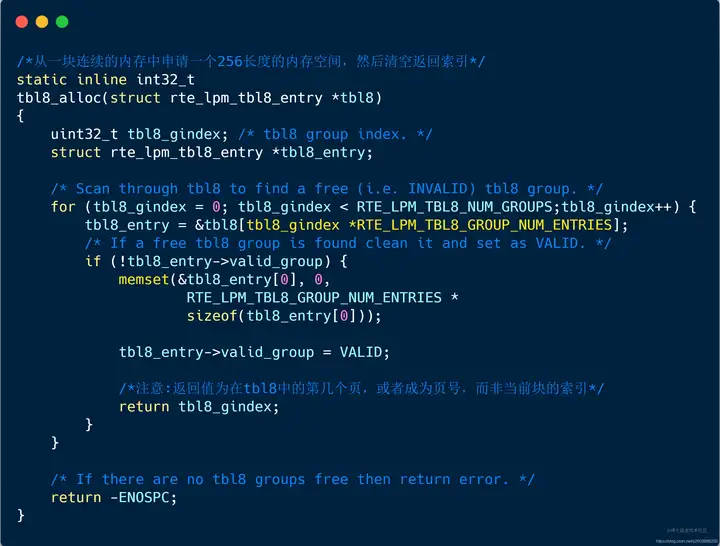 |
| 159 | + |
| 160 | +#### 3.2.4 add_depth_small |
| 161 | + |
| 162 | +首先是获取IP的高24位, 从而可以根据索引直接找到tbl24中的对应项。由于添加的路由子网掩码可能小于24, 例如:192.168.32.0/20, 它在tbl24表中存在多个表项(掩码越短,对应的条目越多),因此需要将涉及的子网都进行修改。 |
| 163 | + |
| 164 | +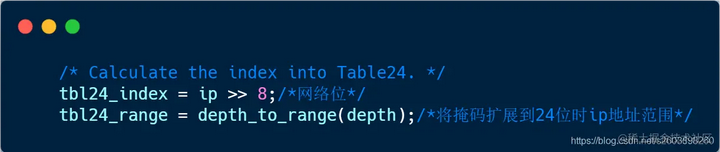 |
| 165 | + |
| 166 | +由于需要更新该子网下的小子网的信息,因此遍历所有小子网条目,逐条修改: |
| 167 | + |
| 168 | +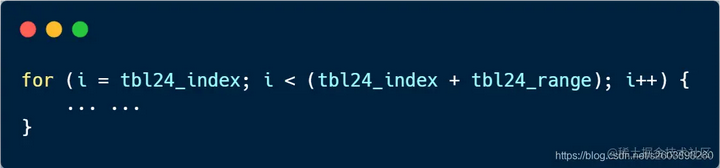 |
| 169 | + |
| 170 | + 添加时分为两部分:**先修改tbl24表,再修改tbl8表**。 |
| 171 | + |
| 172 | +- 在tbl24中没有此表项(valid=0), 或者有此表项且掩码长度小于当前子网掩码长度,此时需要更新tbl24的下一跳和掩码 |
| 173 | +- 修改完毕tbl24,但是未修改包含tbl8表中的项。比如说先添加一条10.28.1.1/32的路由表项,再添加一条10.28.1.0/24的表项,此时便需要修改tbl8中的一部分路由表项。 |
| 174 | + |
| 175 | +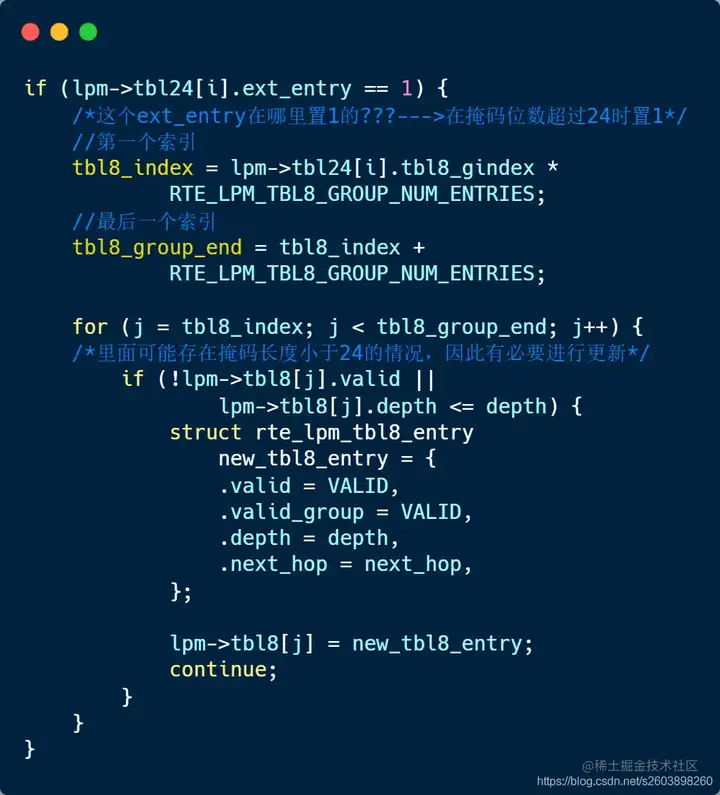 |
| 176 | + |
| 177 | +**以上便是添加掩码长度小于等于24时的情况。下面介绍掩码长度大于24时的情况。** **此函数中又分为三种情况分别处理:** |
| 178 | + |
| 179 | +- **Tbl24** **中没有表项** **(valid=0)** |
| 180 | +- **Tbl24中有条目(valid=1),但是在tbl8中无条目(ext_entry=0)。** |
| 181 | +- 此时需要先添加一个tbl8表,然后将不在目的子网的表项下一跳设置为tbl24的下一跳; |
| 182 | +- 在目的子网的表项更新为新添加的路由表项。 |
| 183 | +- 然后重新关联tbl24和tbl8 |
| 184 | + |
| 185 | +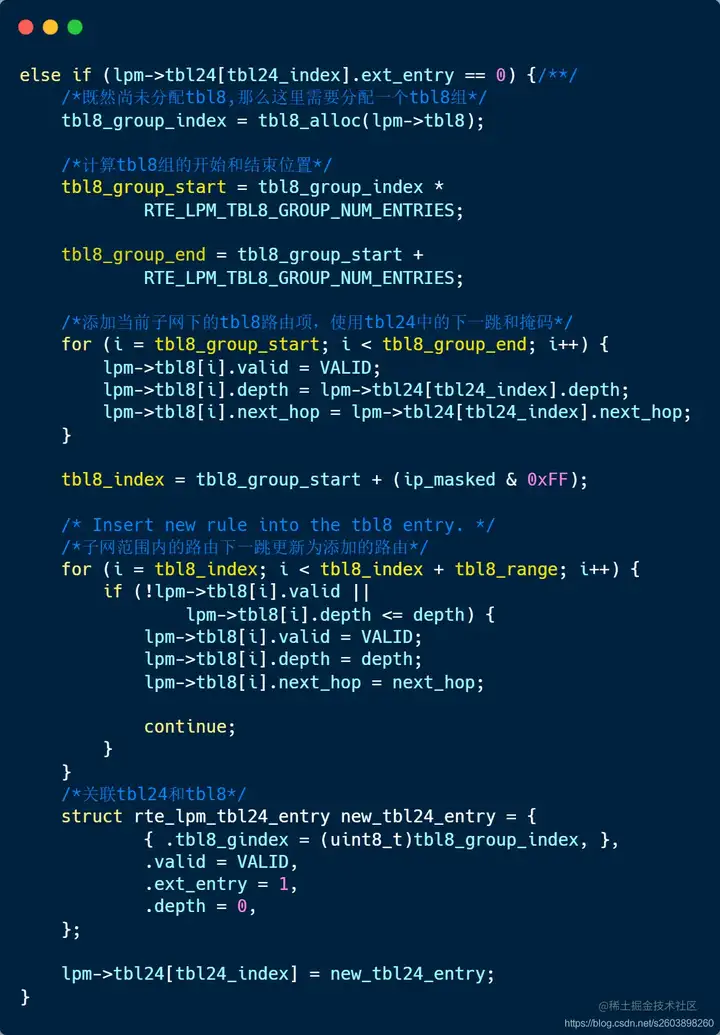 |
| 186 | + |
| 187 | +- **在tbl8中有表项(ext_entry=1)** |
| 188 | +- 这种情况下只需要修改tbl8表中的条目即可,不涉及tbl24表。 |
| 189 | +- 在目的子网范围的所有条目,如果条目无效(valid=0),或者掩码长度小于当前掩码长度(最长掩码匹配原则)时进行更新。 |
| 190 | + |
| 191 | +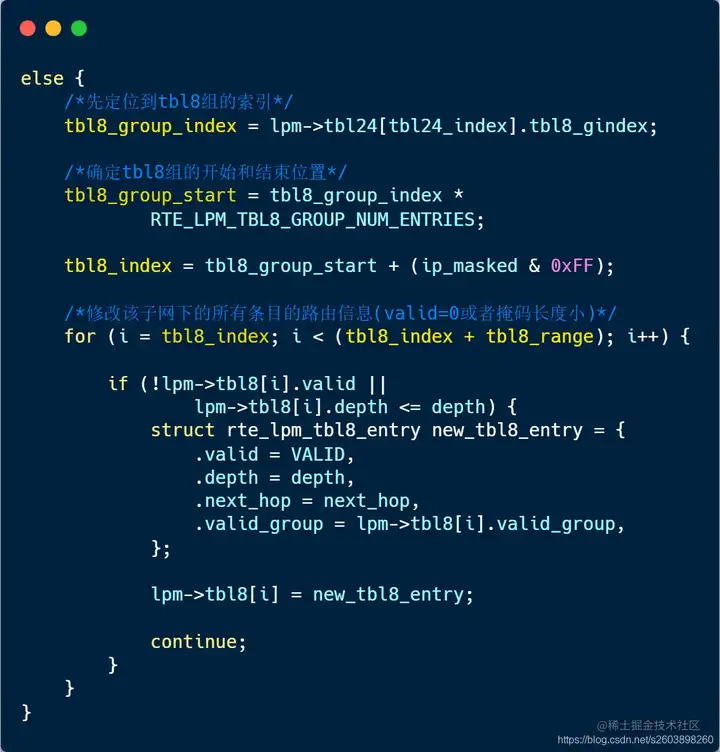 |
| 192 | + |
| 193 | +### 3.3 LPM路由规则删除 |
| 194 | + |
| 195 | +**路由的删除应该也是最能体现算法效率的地方**。如何在删除一个路由后,能快速更新相关子网的路由信息这是问题的关键。 |
| 196 | + |
| 197 | +例如:在删除第一条路由时,此子网的下一跳该设置为多少? 虽然我们已经知道遵循最长掩码匹配原则,但是在实现过程中出现了多种优秀的算法。这里主要看看DPDK是如何实现LPM删除的。 |
| 198 | + |
| 199 | +| | | |
| 200 | +| ---------------- | --------- | |
| 201 | +| 目的子网 | 下一跳 | |
| 202 | +| 192.168.100.0/24 | 10.28.1.1 | |
| 203 | +| 192.168.100.4/30 | 10.28.2.1 | |
| 204 | +| 192.168.0.0/16 | 10.28.3.1 | |
| 205 | + |
| 206 | + 删除操作比添加更为复杂些,因为不仅需要删除,还需要找接盘侠。 3.4.1 rte_lpm_delete 此函数用来删除路由,它的基本逻辑如下: |
| 207 | + |
| 208 | +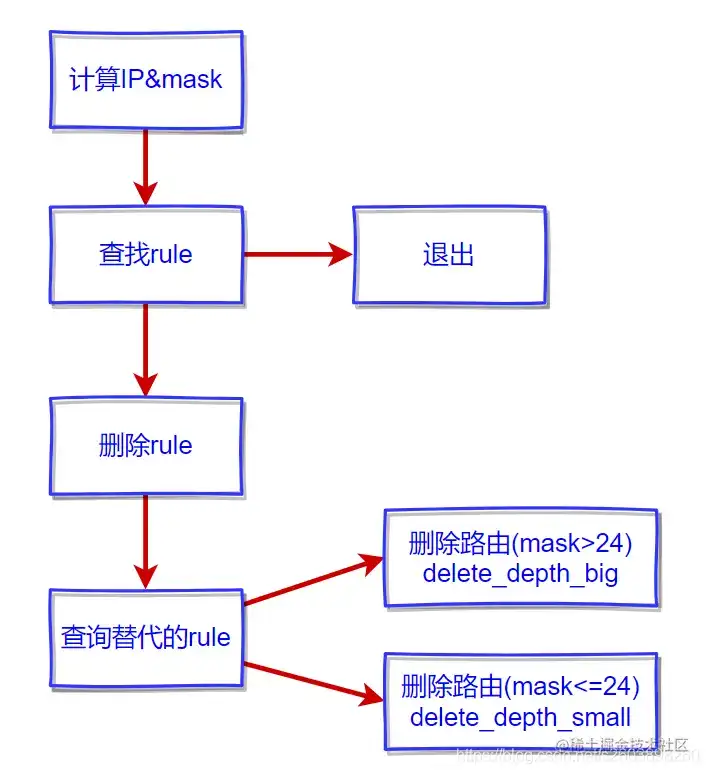 |
| 209 | + |
| 210 | + 代码如下: |
| 211 | + |
| 212 | + |
| 213 | + |
| 214 | +#### 3.3.2 rule_find实现: |
| 215 | + |
| 216 | +rule_find函数实现比较简单,它首先根据掩码长度(depth)确定rule所在ruleTable中的位置(first_rule)以及区间范围[first_rule, first_rule+used_rules], 然后遍历此范围内的所有rules,直到找到匹配的新rule(ip_masked相等即匹配成功)。 |
| 217 | + |
| 218 | +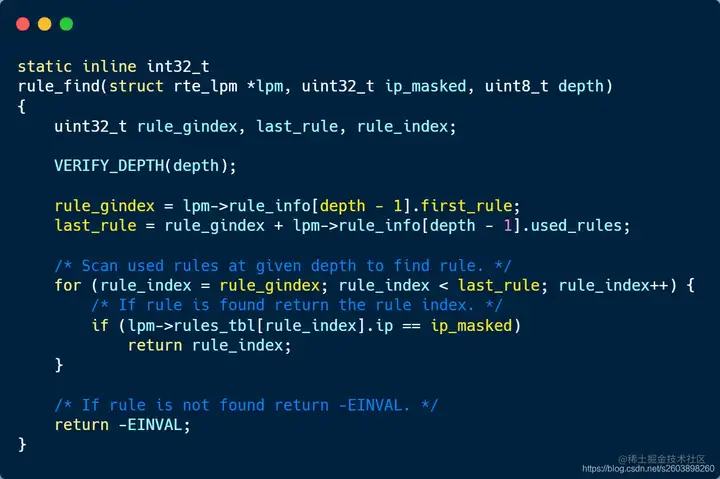 |
| 219 | + |
| 220 | +#### 3.3.3 rule_delete实现 |
| 221 | + |
| 222 | +**由于** **rule** **是通过数组来维护存储的** **(** **有点类似链表的顺序存储,可以快速查询** **)** ,因此在删除之后需要将后续节点进行移动。但是考虑到大量内存拷贝导致的效率低下问题,dpdk采用了有限个元素移动:因为每次只删除一个rule,后续每一个rule组只需向前移动一个节点即可,无需全部移动。明白了这个原则,看代码就会容易很多 |
| 223 | + |
| 224 | +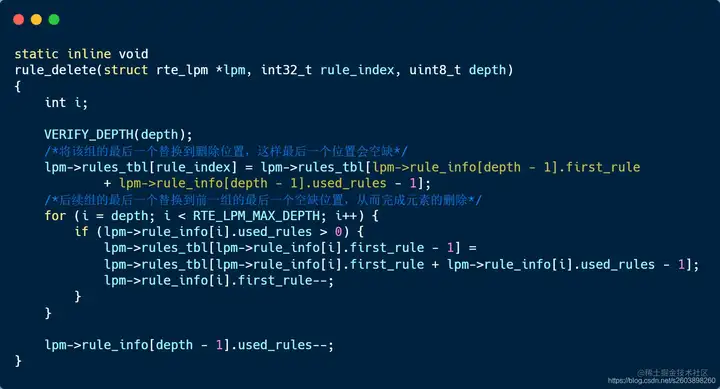 |
| 225 | + |
| 226 | +#### 3.3.4 Find_previous_rule实现 |
| 227 | + |
| 228 | +它是用来查找前一条路由。由于需要删除当前路由,而此子网下的路由需要重新查询更新,查询的原则是:**从掩码长度** **<=depth-1** **开始递减** **(** **因为遵循最长掩码匹配,因此需要从最大的开始匹配** **)** 。如果存在包含当前子网的路由,则返回此路由的索引(rule_index)。 |
| 229 | + |
| 230 | +#### 3.3.5 delete_depth_small实现: 当掩码长度≤24时,删除路由时分为两种情况进行: |
| 231 | + |
| 232 | +- **不存在此路由**。此时需要删除该子网下所有条目的路由信息,既包括tbl24表也包括tbl8表中条目。 |
| 233 | + |
| 234 | +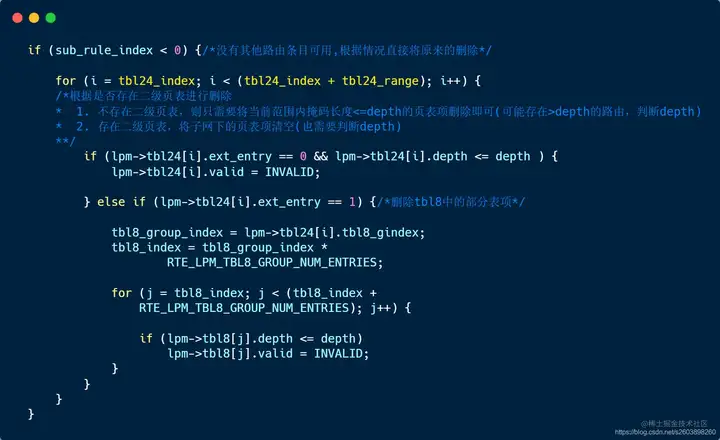 |
| 235 | + |
| 236 | +- **存在替代路由**;此时需要将删除子网的条目下一跳更改为替代的路由下一跳(最长掩码匹配到的路由) |
| 237 | + |
| 238 | + **如果只使用了tbl24表,则只需要修改tbl24;** **如果同时使用了tbl8表,则需要将tbl8表条目全部修改。** |
| 239 | + |
| 240 | + |
| 241 | + |
| 242 | +#### 3.3.6 delete_depth_big实现: 当掩码长度大于24时,使用此接口删除路由。当掩码长度大于24,此时主要涉及tbl8表项,因此主要操作对象为tbl8。该函数也分为两个情况进行处理: |
| 243 | + |
| 244 | +- **不存在替代路由**。将子网范围内的表项全部清除(valid=0) |
| 245 | + |
| 246 | +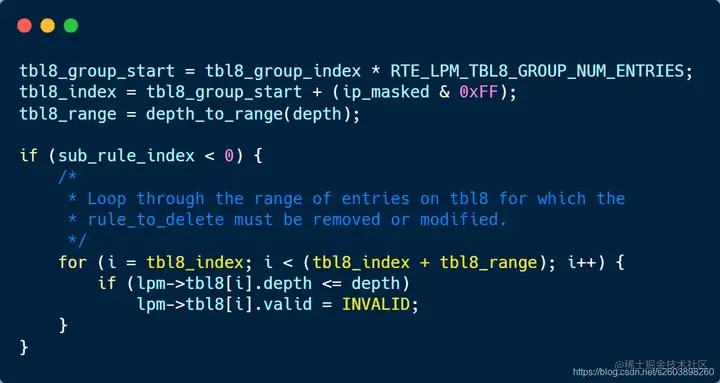 |
| 247 | + |
| 248 | +- **存在替代路由**。更新子网范围内的表项。 |
| 249 | + |
| 250 | +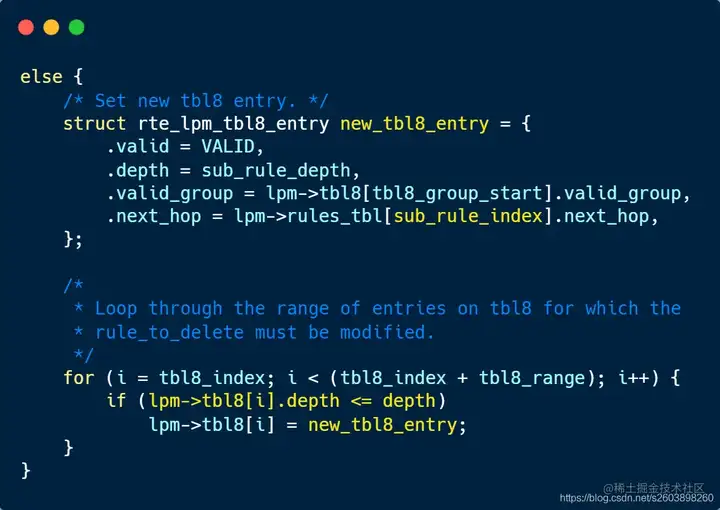 |
| 251 | + |
| 252 | +此外由于删除路由后,tlb8二级表可能已经无可用路由,因此需要将其释放,节省空间。 |
| 253 | + |
| 254 | +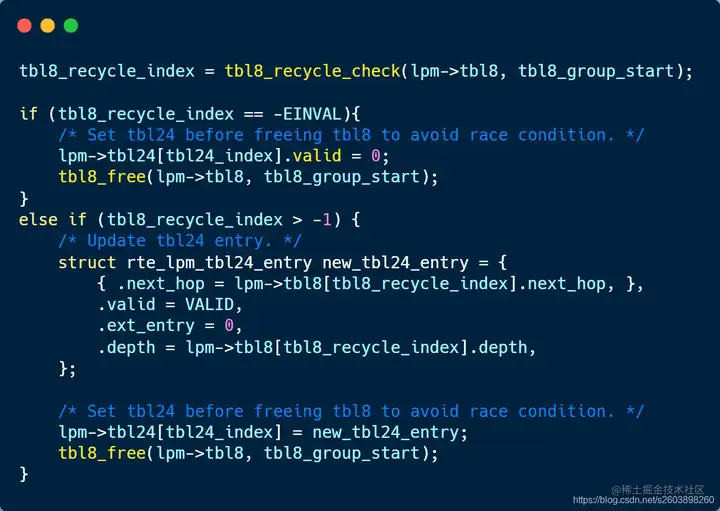 |
| 255 | + |
| 256 | +### 3.4 LPM路由清空 |
| 257 | + |
| 258 | +清空操作比较容易,由于是连续地址空间,只需要将lpm结构清空即可。 |
| 259 | + |
| 260 | +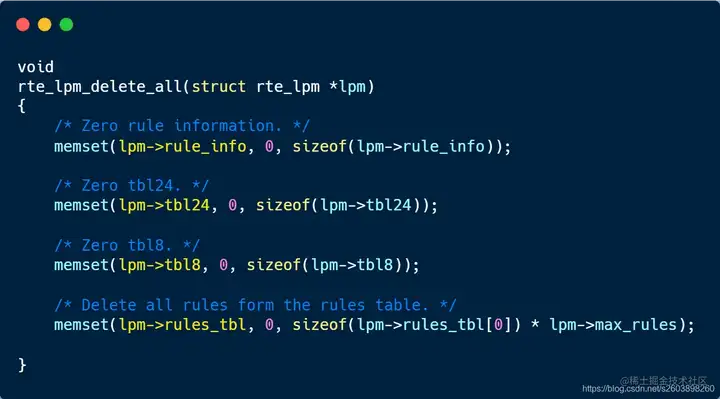 |
| 261 | + |
| 262 | +## 4. 小结 |
| 263 | + |
| 264 | +我不妥协,只因为我坚信我可以做的更好。 花了两天时间整理出来的流程,不敢说多么详细,但是应该是比较详细的。从这里面学到了以前长吐槽的一点:**链表使用链式存储多方便,为啥要写顺序存储的链表**。以前没有在实际工程中见过,不知道原因,这次是深深体会到了,他除了操作起来比较复杂,但是速度快,效率高呀,DPDK也许就时在所有可能优化的点上做到了极致才得到了各大厂商的青睐。 “最长掩码匹配原则”这个词看到过很多遍,但从未看过它的实现,因为日常完全不会让我们去实现,但是通过阅读这个LPM源码,发现对于我们习以为常的经典算法应该好好研读,不是为了自己开发一套,而是为了以后能够写出更好地代码,写出更高深的bug。 纸上得来终觉浅,绝知此事要躬行。 |
0 commit comments