You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
Copy file name to clipboardExpand all lines: README.md
+2-1Lines changed: 2 additions & 1 deletion
Original file line number
Diff line number
Diff line change
@@ -2,6 +2,7 @@
2
2
3
3
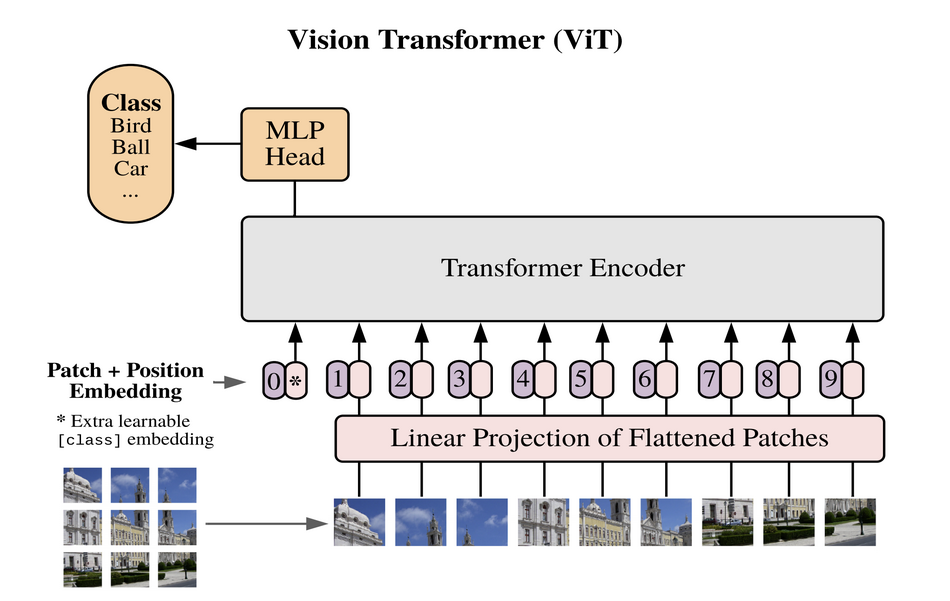
This is an implementation of ViT - Vision Transformer by Google Research Team through the paper [**"An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale"**](https://arxiv.org/abs/2010.11929)
4
4
5
+
**Please install PyTorch with CUDA support following this [link](https://pytorch.org/get-started/locally/)**
5
6
6
7
## ViT Architecture
7
8
@@ -29,8 +30,8 @@ cls #pool
29
30
## Training
30
31
Currently, you can only train this model on CIFAR-100 with the following commands:
0 commit comments