|
| 1 | +# 从0开始服务化-0-调用链-Zipkin |
| 2 | + |
| 3 | +## Zipkin |
| 4 | + |
| 5 | +`Zipkin` 是一个分布式跟踪系统,用于收集、管理和查找跟踪数据。它可以把分布式链路调用的顺序串起来,并计算链路中每个 `RPC` 调用的耗时,可以很直观的看出在整个调用链路中延迟问题。 `Zipkin` 的设计基于 `GoogleDapper` 论文实现的。 |
| 6 | + |
| 7 | +`ZipkinServer` 提供了 `UI` 操作,可以非常方便地查看和搜索跟踪数据,直观的查看到链调用依赖关系。 |
| 8 | + |
| 9 | +该项目包括一个无依赖库和一个 `spring-boot` 服务器。存储支持包括内存, `JDBC(mysql)`, `Cassandra` 和 `Elasticsearch` 。 |
| 10 | + |
| 11 | +在没有使用外部存储时,则默认使用内存存储数据,内存数据是有限且不可持久化的,所以建议使用外部存储,因日志数据通常很大,为了搜索日志的效率,所以建议使用 `Elasticsearch` 。 |
| 12 | + |
| 13 | +Zipkin 的基础架构由 4 个核心组件构成: |
| 14 | + |
| 15 | +- `Collector`:收集器组件,处理从外部系统发过来的跟踪信息,将这些信息转换为 Zipkin 内部处理的 Span 格式,以支持后续的存储、分析、展示等功能。 |
| 16 | +- `Stroage`:存储组件,主要处理收集器收到的跟踪信息,默认存储在内存中,也可通过 ES 或 JDBC 来存储。 |
| 17 | +- `Restful API`:API 组件,提供外部访问接口。 |
| 18 | +- `Web UI`:UI组件,基于 API 组件实现的 Web 控制台,用户可以很方便直观地查询、搜索和分析跟踪信息。 |
| 19 | + |
| 20 | +## 部署测试服务 |
| 21 | + |
| 22 | +使用 `docker` 部署本地 `zipkin` 的 `server` 端 |
| 23 | + |
| 24 | +``` |
| 25 | +docker run -d -p 9411:9411 \ |
| 26 | +--name zipkin \ |
| 27 | +docker.io/openzipkin/zipkin |
| 28 | +``` |
| 29 | + |
| 30 | + |
| 31 | + |
| 32 | +访问:`http://localhost:9411/zipkin/` |
| 33 | + |
| 34 | + |
| 35 | + |
| 36 | +## 构建测试项目 |
| 37 | + |
| 38 | +- Service A |
| 39 | + |
| 40 | + ``` |
| 41 | + server: |
| 42 | + port: 8081 |
| 43 | +
|
| 44 | + spring: |
| 45 | + application: |
| 46 | + name: server-a |
| 47 | + sleuth: |
| 48 | + web: |
| 49 | + client: |
| 50 | + enabled: true |
| 51 | + sampler: |
| 52 | + probability: 1.0 # 采用比例,默认 0.1 全部采样 1.0 |
| 53 | + zipkin: |
| 54 | + base-url: http://localhost:9411/ # 指定了Zipkin服务器的地址 |
| 55 | + ``` |
| 56 | +
|
| 57 | + ``` |
| 58 | + @Slf4j |
| 59 | + @RestController |
| 60 | + public class ServiceAController { |
| 61 | +
|
| 62 | + @Resource |
| 63 | + private RestTemplate restTemplate; |
| 64 | +
|
| 65 | + @GetMapping(value = "/servicea") |
| 66 | + public String servicea() { |
| 67 | + try { |
| 68 | + Thread.sleep(3000); |
| 69 | + } catch (InterruptedException e) { |
| 70 | + e.printStackTrace(); |
| 71 | + } |
| 72 | + log.info("This is service a!"); |
| 73 | + return restTemplate.getForObject("http://localhost:8082/serviceb", String.class); |
| 74 | + } |
| 75 | + } |
| 76 | + ``` |
| 77 | +
|
| 78 | +- Service B |
| 79 | +
|
| 80 | + ``` |
| 81 | + server: |
| 82 | + port: 8082 |
| 83 | +
|
| 84 | + spring: |
| 85 | + application: |
| 86 | + name: server-b |
| 87 | + sleuth: |
| 88 | + web: |
| 89 | + client: |
| 90 | + enabled: true |
| 91 | + sampler: |
| 92 | + probability: 1.0 # 采用比例,默认 0.1 全部采样 1.0 |
| 93 | + zipkin: |
| 94 | + base-url: http://localhost:9411/ # 指定了Zipkin服务器的地址 |
| 95 | + ``` |
| 96 | +
|
| 97 | + ``` |
| 98 | + @Slf4j |
| 99 | + @RestController |
| 100 | + public class ServiceBController { |
| 101 | +
|
| 102 | + @Autowired |
| 103 | + private RestTemplate restTemplate; |
| 104 | +
|
| 105 | + @GetMapping(value = "/serviceb") |
| 106 | + public String serviceb() { |
| 107 | + try { |
| 108 | + Thread.sleep(3000); |
| 109 | + } catch (InterruptedException e) { |
| 110 | + e.printStackTrace(); |
| 111 | + } |
| 112 | + log.info("This is service b!"); |
| 113 | + return restTemplate.getForObject("http://localhost:8083/servicec", String.class); |
| 114 | + } |
| 115 | + } |
| 116 | + ``` |
| 117 | +
|
| 118 | +- Service C |
| 119 | +
|
| 120 | + ``` |
| 121 | + server: |
| 122 | + port: 8083 |
| 123 | +
|
| 124 | + spring: |
| 125 | + application: |
| 126 | + name: server-c |
| 127 | + sleuth: |
| 128 | + web: |
| 129 | + client: |
| 130 | + enabled: true |
| 131 | + sampler: |
| 132 | + probability: 1.0 # 采用比例,默认 0.1 全部采样 1.0 |
| 133 | + zipkin: |
| 134 | + base-url: http://localhost:9411/ # 指定了Zipkin服务器的地址 |
| 135 | + ``` |
| 136 | +
|
| 137 | + ``` |
| 138 | + @Slf4j |
| 139 | + @RestController |
| 140 | + public class ServiceCController { |
| 141 | +
|
| 142 | + @Resource |
| 143 | + private RestTemplate restTemplate; |
| 144 | +
|
| 145 | + @GetMapping(value = "/servicec") |
| 146 | + public String servicec() { |
| 147 | + try { |
| 148 | + Thread.sleep(3000); |
| 149 | + } catch (InterruptedException e) { |
| 150 | + e.printStackTrace(); |
| 151 | + } |
| 152 | + log.info("This is service c!"); |
| 153 | + return "hello,this is server c!"; |
| 154 | + } |
| 155 | + } |
| 156 | + ``` |
| 157 | +
|
| 158 | +## 测试服务调用链-Sleuth |
| 159 | +
|
| 160 | +`Zipkin` 的依赖中包含了 `Sleuth`,`Sleuth` 功能: |
| 161 | +
|
| 162 | +- 将 `SpanID` 和 `TraceID` 添加到 `Slf4JMDC` 中,这样可以在日志聚合器中根据 `SpanID` 和 `TraceID` 提取日志。 |
| 163 | +- 提供对常见分布式跟踪数据模型的抽象:`traces(跟踪)`, `spans(形成DAG(有向无环图))`,注释, `key-value` 注释。松散地基于 `HTrace` ,但兼容 `Zipkin(Dapper)`。 |
| 164 | +- `Sleuth` 常见的入口和出口点来自 `Spring` 应用(`Servlet` 过滤器、`Rest Template`、`Scheduled Actions`、消息通道、`Zuul Filter、`Feign Client`)。 |
| 165 | +- 如果 `spring-cloud-sleuth-zipkin` 可用,`Sleuth` 将通过 `HTTP` 生成并收集与 `Zipkin` 兼容的跟踪。默认情况下,将跟踪数据发送到 `localhost`(端口:9411)上的 `Zipkin` 收集服务应用,可使用 `spring.zipkin.baseUrl` 修改服务器地址。 |
| 166 | +
|
| 167 | +启动3个服务,访问:`http://localhost:8081/servicea`,可以看到3个服务的日志输出如下: |
| 168 | +
|
| 169 | + |
| 170 | +
|
| 171 | + |
| 172 | +
|
| 173 | + |
| 174 | +
|
| 175 | +在输出的日志中,多了些内容,这些内容就是由 `sleuth` 为服务调用提供的链路信息 |
| 176 | +可以看到内容组成:`[appname,traceId,spanId,exportable]`,具体含义如下: |
| 177 | +
|
| 178 | +- `appname`:服务的名称,即 spring.application.name 的值。 |
| 179 | +- `traceId`:整个请求链路的唯一ID。 |
| 180 | +- `spanId`:基本的工作单元,一个 RPC 调用就是一个新的 span。启动跟踪的初始 span 称为 root span ,此 spanId 的值与 traceId 的值相同。见上面示例消费者服务日志输出。 |
| 181 | +- `exportable`:是否将数据导入到 Zipkin 中,true 表示导入成功,false 表示导入失败。 |
| 182 | +
|
| 183 | +## Zipkin Server |
| 184 | +
|
| 185 | +再次访问:`http://localhost:9411/zipkin/`,点击查询,可以看到刚才执行的服务调用链: |
| 186 | +
|
| 187 | +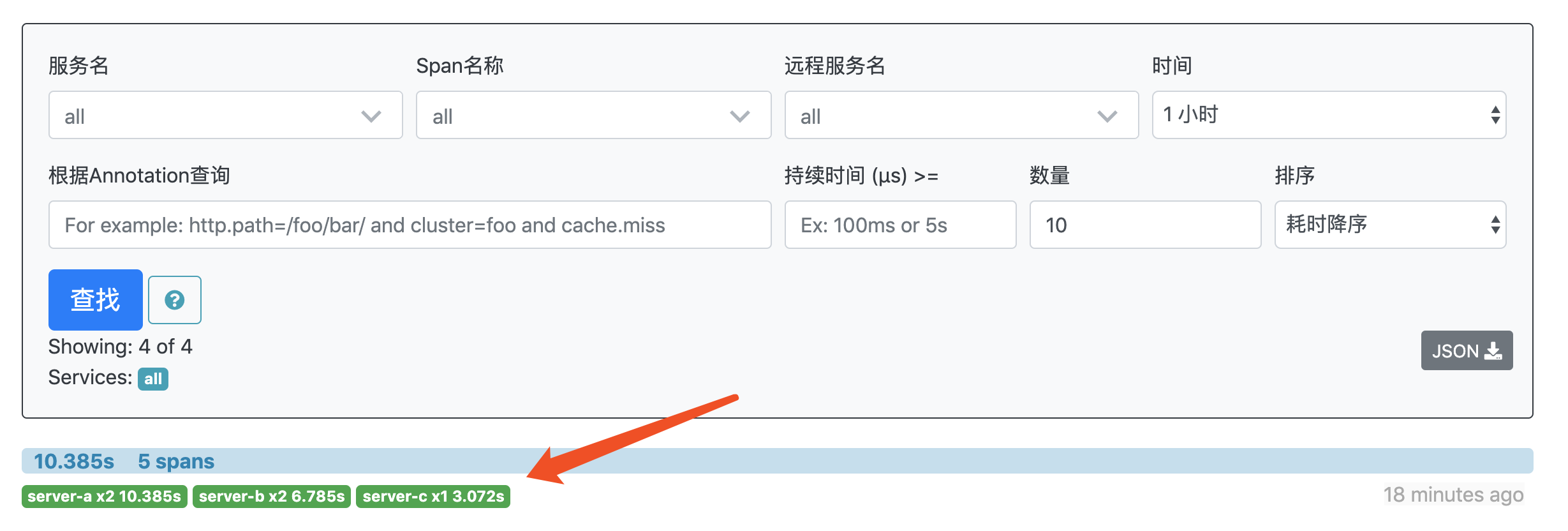 |
| 188 | +
|
| 189 | +点击可以看到具体的调用时间与链路: |
| 190 | +
|
| 191 | +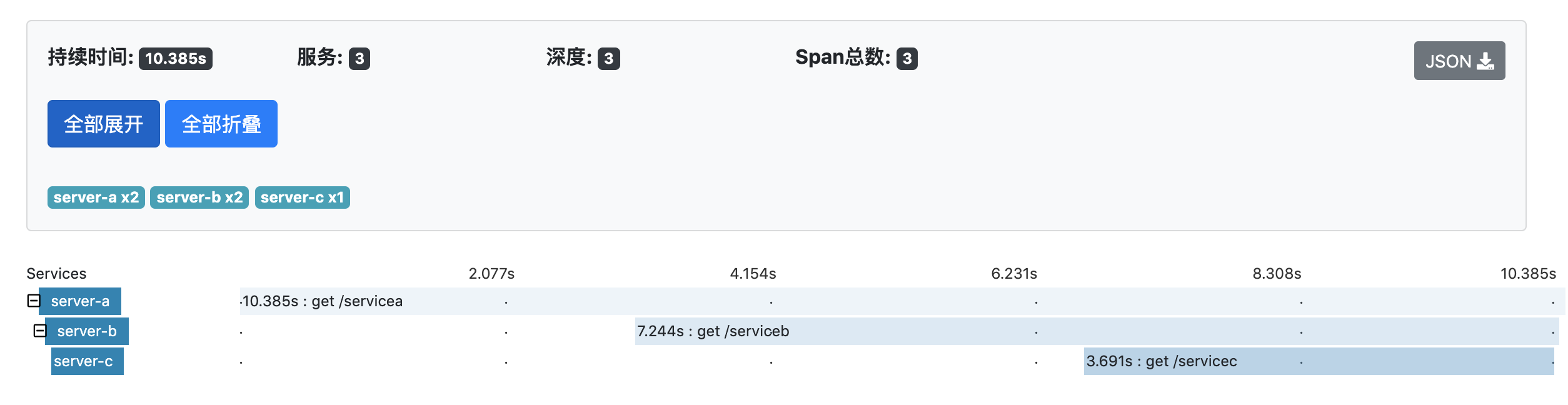 |
| 192 | +
|
| 193 | +点击具体的服务,可以看到服务调用的详情以及父级子级 `trace` |
| 194 | +
|
| 195 | +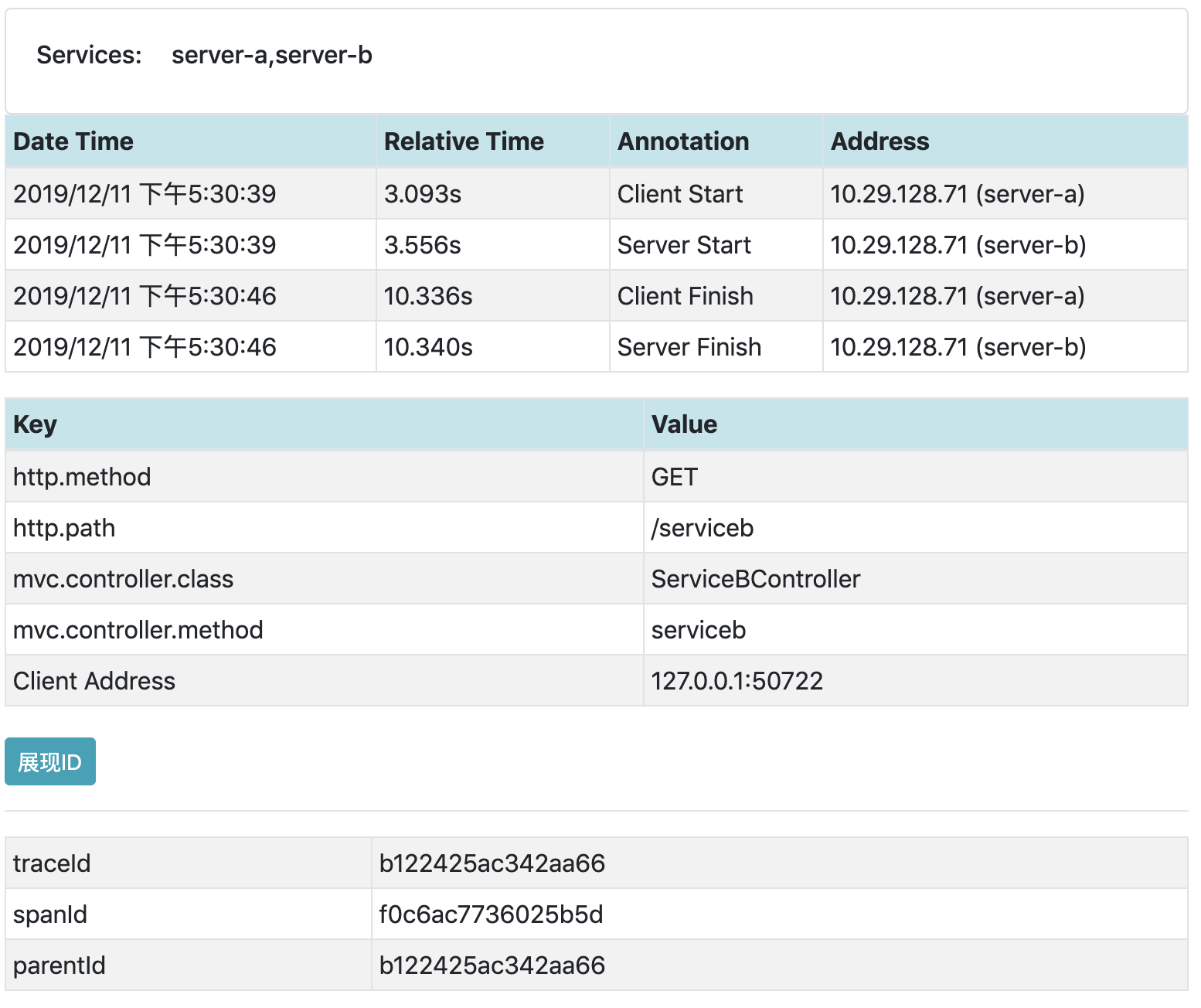 |
0 commit comments