|
52 | 52 | on mesos(集群模式): 运行在 mesos 资源管理器框架之上,由 mesos 负责资源管理,Spark 负责任务调度和计算 |
53 | 53 | on cloud(集群模式):比如 AWS 的 EC2,使用这个模式能很方便的访问 Amazon的 S3;Spark 支持多种分布式存储系统:HDFS 和 S3 |
54 | 54 | ### 5 HDFS读写数据的过程 |
55 | | - 读: |
56 | | - 1、跟namenode通信查询元数据,找到文件块所在的datanode服务器 |
57 | | - 2、挑选一台datanode(就近原则,然后随机)服务器,请求建立socket流 |
58 | | - 3、datanode开始发送数据(从磁盘里面读取数据放入流,以packet为单位来做校验) |
59 | | - 4、客户端以packet为单位接收,现在本地缓存,然后写入目标文件 |
60 | | - 写: |
61 | | - 1、根namenode通信请求上传文件,namenode检查目标文件是否已存在,父目录是否存在 |
62 | | - 2、namenode返回是否可以上传 |
63 | | - 3、client请求第一个 block该传输到哪些datanode服务器上 |
64 | | - 4、namenode返回3个datanode服务器ABC |
65 | | - 5、client请求3台dn中的一台A上传数据(本质上是一个RPC调用,建立pipeline),A收到请求会继续调用B,然后B调用C,将真个pipeline建立完成,逐级返回客户端 |
66 | | - 6、client开始往A上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位,A收到一个packet就会传给B,B传给C;A每传一个packet会放入一个应答队列等待应答 |
67 | | - 7、当一个block传输完成之后,client再次请求namenode上传第二个block的服务器。 |
| 55 | + **读:** |
| 56 | + 1、跟namenode通信查询元数据,找到文件块所在的datanode服务器 |
| 57 | + 2、挑选一台datanode(就近原则,然后随机)服务器,请求建立socket流 |
| 58 | + 3、datanode开始发送数据(从磁盘里面读取数据放入流,以packet为单位来做校验) |
| 59 | + 4、客户端以packet为单位接收,现在本地缓存,然后写入目标文件 |
| 60 | + 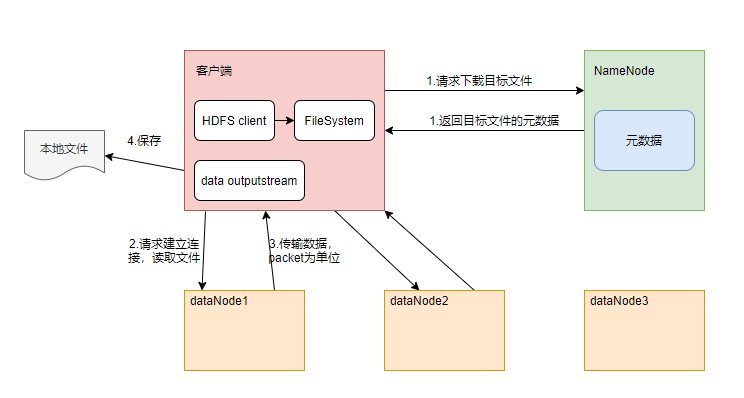 |
| 61 | + |
| 62 | + **写:** |
| 63 | + 1、根namenode通信请求上传文件,namenode检查目标文件是否已存在,父目录是否存在 |
| 64 | + 2、namenode返回是否可以上传 |
| 65 | + 3、client请求第一个 block该传输到哪些datanode服务器上 |
| 66 | + 4、namenode返回3个datanode服务器ABC |
| 67 | + 5、client请求3台dn中的一台A上传数据(本质上是一个RPC调用,建立pipeline),A收到请求会继续调用B,然后B调用C,将真个pipeline建立完成,逐级返回客户端 |
| 68 | + 6、client开始往A上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位,A收到一个packet就会传给B,B传给C;A每传一个packet会放入一个应答队列等待应答 |
| 69 | + 7、当一个block传输完成之后,client再次请求namenode上传第二个block的服务器。 |
| 70 | +  |
| 71 | + |
68 | 72 | ### 6 RDD中reduceBykey与groupByKey哪个性能好,为什么 |
69 | 73 | reduceByKey:reduceByKey会在结果发送至reducer之前会对每个mapper在本地进行merge,有点类似于在MapReduce中的combiner。这样做的好处在于,在map端进行一次reduce之后,数据量会大幅度减小,从而减小传输,保证reduce端能够更快的进行结果计算。 |
70 | 74 | groupByKey:groupByKey会对每一个RDD中的value值进行聚合形成一个序列(Iterator),此操作发生在reduce端,所以势必会将所有的数据通过网络进行传输,造成不必要的浪费。同时如果数据量十分大,可能还会造成OutOfMemoryError。 |
|
0 commit comments