|
| 1 | +# PCam (PatchCamelyon) |
| 2 | + |
| 3 | +## Description |
| 4 | + |
| 5 | +This project supports **`Patch Camelyon (PCam) `**, which can be downloaded from [here](https://opendatalab.com/PCam). |
| 6 | + |
| 7 | +### Dataset Overview |
| 8 | + |
| 9 | +PatchCamelyon is an image classification dataset. It consists of 327680 color images (96 x 96px) extracted from histopathologic scans of lymph node sections. Each image is annotated with a binary label indicating presence of metastatic tissue. PCam provides a new benchmark for machine learning models: bigger than CIFAR10, smaller than ImageNet, trainable on a single GPU. |
| 10 | + |
| 11 | +### Statistic Information |
| 12 | + |
| 13 | +| Dataset Name | Anatomical Region | Task Type | Modality | Num. Classes | Train/Val/Test images | Train/Val/Test Labeled | Release Date | License | |
| 14 | +| ------------------------------------ | ----------------- | ------------ | -------------- | ------------ | --------------------- | ---------------------- | ------------ | ------------------------------------------------------------- | |
| 15 | +| [Pcam](https://opendatalab.com/PCam) | throax | segmentation | histopathology | 2 | 327680/-/- | yes/-/- | 2018 | [CC0 1.0](https://creativecommons.org/publicdomain/zero/1.0/) | |
| 16 | + |
| 17 | +| Class Name | Num. Train | Pct. Train | Num. Val | Pct. Val | Num. Test | Pct. Test | |
| 18 | +| :---------------: | :--------: | :--------: | :------: | :------: | :-------: | :-------: | |
| 19 | +| background | 214849 | 63.77 | - | - | - | - | |
| 20 | +| metastatic tissue | 131832 | 36.22 | - | - | - | - | |
| 21 | + |
| 22 | +Note: |
| 23 | + |
| 24 | +- `Pct` means percentage of pixels in this category in all pixels. |
| 25 | + |
| 26 | +### Visualization |
| 27 | + |
| 28 | +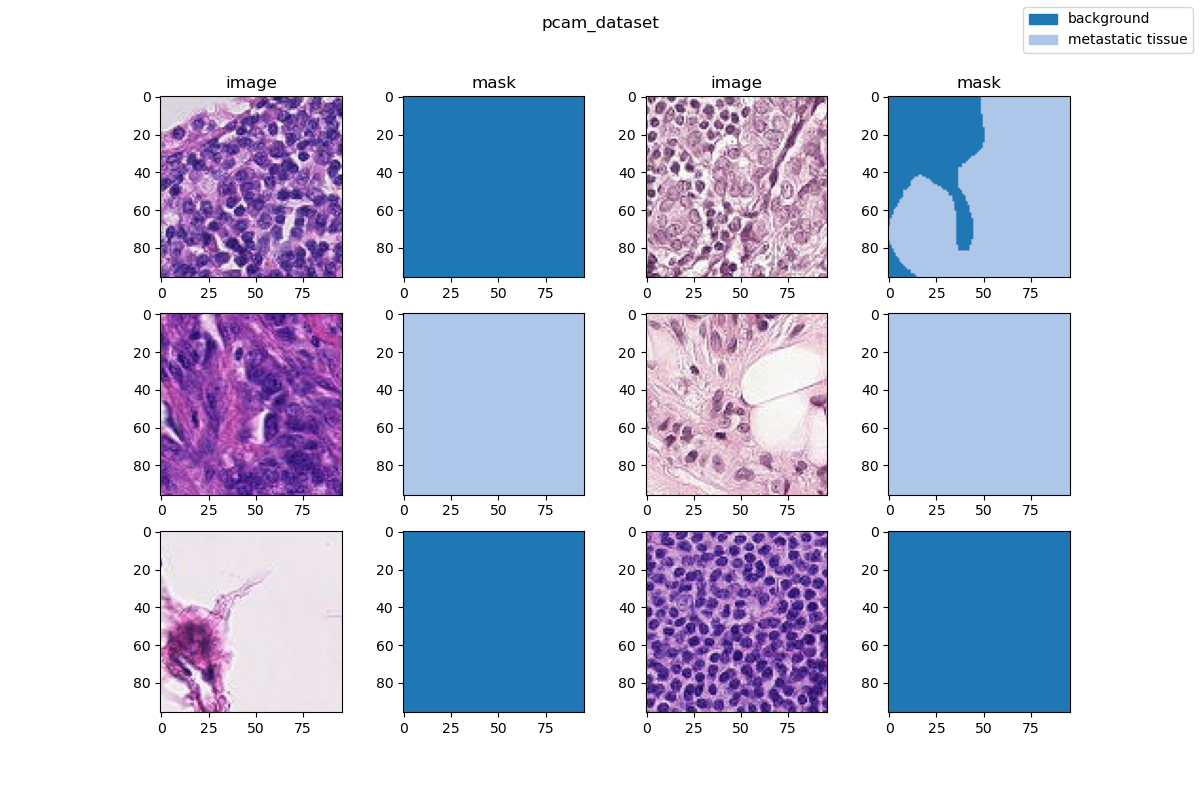 |
| 29 | + |
| 30 | +### Dataset Citation |
| 31 | + |
| 32 | +``` |
| 33 | +@inproceedings{veeling2018rotation, |
| 34 | + title={Rotation equivariant CNNs for digital pathology}, |
| 35 | + author={Veeling, Bastiaan S and Linmans, Jasper and Winkens, Jim and Cohen, Taco and Welling, Max}, |
| 36 | + booktitle={International Conference on Medical image computing and computer-assisted intervention}, |
| 37 | + pages={210--218}, |
| 38 | + year={2018}, |
| 39 | +} |
| 40 | +``` |
| 41 | + |
| 42 | +### Prerequisites |
| 43 | + |
| 44 | +- Python v3.8 |
| 45 | +- PyTorch v1.10.0 |
| 46 | +- pillow(PIL) v9.3.0 9.3.0 |
| 47 | +- scikit-learn(sklearn) v1.2.0 1.2.0 |
| 48 | +- [MIM](https://github.com/open-mmlab/mim) v0.3.4 |
| 49 | +- [MMCV](https://github.com/open-mmlab/mmcv) v2.0.0rc4 |
| 50 | +- [MMEngine](https://github.com/open-mmlab/mmengine) v0.2.0 or higher |
| 51 | +- [MMSegmentation](https://github.com/open-mmlab/mmsegmentation) v1.0.0rc5 |
| 52 | + |
| 53 | +All the commands below rely on the correct configuration of `PYTHONPATH`, which should point to the project's directory so that Python can locate the module files. In `pcam/` root directory, run the following line to add the current directory to `PYTHONPATH`: |
| 54 | + |
| 55 | +```shell |
| 56 | +export PYTHONPATH=`pwd`:$PYTHONPATH |
| 57 | +``` |
| 58 | + |
| 59 | +### Dataset Preparing |
| 60 | + |
| 61 | +- download dataset from [here](https://opendatalab.com/PCam) and decompress data to path `'data/'`. |
| 62 | +- run script `"python tools/prepare_dataset.py"` to format data and change folder structure as below. |
| 63 | +- run script `"python ../../tools/split_seg_dataset.py"` to split dataset and generate `train.txt`, `val.txt` and `test.txt`. If the label of official validation set and test set cannot be obtained, we generate `train.txt` and `val.txt` from the training set randomly. |
| 64 | + |
| 65 | +```shell |
| 66 | +mkdir data & cd data |
| 67 | +pip install opendatalab |
| 68 | +odl get PCam |
| 69 | +mv ./PCam/raw/pcamv1 ./ |
| 70 | +rm -rf PCam |
| 71 | +cd .. |
| 72 | +python tools/prepare_dataset.py |
| 73 | +python ../../tools/split_seg_dataset.py |
| 74 | +``` |
| 75 | + |
| 76 | +```none |
| 77 | + mmsegmentation |
| 78 | + ├── mmseg |
| 79 | + ├── projects |
| 80 | + │ ├── medical |
| 81 | + │ │ ├── 2d_image |
| 82 | + │ │ │ ├── histopathology |
| 83 | + │ │ │ │ ├── pcam |
| 84 | + │ │ │ │ │ ├── configs |
| 85 | + │ │ │ │ │ ├── datasets |
| 86 | + │ │ │ │ │ ├── tools |
| 87 | + │ │ │ │ │ ├── data |
| 88 | + │ │ │ │ │ │ ├── train.txt |
| 89 | + │ │ │ │ │ │ ├── val.txt |
| 90 | + │ │ │ │ │ │ ├── images |
| 91 | + │ │ │ │ │ │ │ ├── train |
| 92 | + │ │ │ │ | │ │ │ ├── xxx.png |
| 93 | + │ │ │ │ | │ │ │ ├── ... |
| 94 | + │ │ │ │ | │ │ │ └── xxx.png |
| 95 | + │ │ │ │ │ │ ├── masks |
| 96 | + │ │ │ │ │ │ │ ├── train |
| 97 | + │ │ │ │ | │ │ │ ├── xxx.png |
| 98 | + │ │ │ │ | │ │ │ ├── ... |
| 99 | + │ │ │ │ | │ │ │ └── xxx.png |
| 100 | +``` |
| 101 | + |
| 102 | +### Divided Dataset Information |
| 103 | + |
| 104 | +***Note: The table information below is divided by ourselves.*** |
| 105 | + |
| 106 | +| Class Name | Num. Train | Pct. Train | Num. Val | Pct. Val | Num. Test | Pct. Test | |
| 107 | +| :---------------: | :--------: | :--------: | :------: | :------: | :-------: | :-------: | |
| 108 | +| background | 171948 | 63.82 | 42901 | 63.6 | - | - | |
| 109 | +| metastatic tissue | 105371 | 36.18 | 26461 | 36.4 | - | - | |
| 110 | + |
| 111 | +### Training commands |
| 112 | + |
| 113 | +To train models on a single server with one GPU. (default) |
| 114 | + |
| 115 | +```shell |
| 116 | +mim train mmseg ./configs/${CONFIG_FILE} |
| 117 | +``` |
| 118 | + |
| 119 | +### Testing commands |
| 120 | + |
| 121 | +To test models on a single server with one GPU. (default) |
| 122 | + |
| 123 | +```shell |
| 124 | +mim test mmseg ./configs/${CONFIG_FILE} --checkpoint ${CHECKPOINT_PATH} |
| 125 | +``` |
| 126 | + |
| 127 | +<!-- List the results as usually done in other model's README. [Example](https://github.com/open-mmlab/mmsegmentation/tree/dev-1.x/configs/fcn#results-and-models) |
| 128 | +
|
| 129 | +You should claim whether this is based on the pre-trained weights, which are converted from the official release; or it's a reproduced result obtained from retraining the model in this project. --> |
| 130 | + |
| 131 | +## Checklist |
| 132 | + |
| 133 | +- [x] Milestone 1: PR-ready, and acceptable to be one of the `projects/`. |
| 134 | + |
| 135 | + - [x] Finish the code |
| 136 | + - [x] Basic docstrings & proper citation |
| 137 | + - [ ] Test-time correctness |
| 138 | + - [x] A full README |
| 139 | + |
| 140 | +- [ ] Milestone 2: Indicates a successful model implementation. |
| 141 | + |
| 142 | + - [ ] Training-time correctness |
| 143 | + |
| 144 | +- [ ] Milestone 3: Good to be a part of our core package! |
| 145 | + |
| 146 | + - [ ] Type hints and docstrings |
| 147 | + - [ ] Unit tests |
| 148 | + - [ ] Code polishing |
| 149 | + - [ ] Metafile.yml |
| 150 | + |
| 151 | +- [ ] Move your modules into the core package following the codebase's file hierarchy structure. |
| 152 | + |
| 153 | +- [ ] Refactor your modules into the core package following the codebase's file hierarchy structure. |
0 commit comments