|
| 1 | +--- |
| 2 | +title: "01-神经网络的压缩与稀疏化优化" |
| 3 | +layout: page |
| 4 | +date: 2099-06-02 00:00 |
| 5 | +--- |
| 6 | +[TOC] |
| 7 | + |
| 8 | +# 1. 神经网络的压缩 |
| 9 | + |
| 10 | +## 1.1. 背景 |
| 11 | +深度神经网络好、有用,非常棒;但是模型复杂度急剧提升 |
| 12 | + |
| 13 | +解决方案: |
| 14 | +1. 模型压缩与稀疏化 |
| 15 | +2. 提升计算性能,材料科学 |
| 16 | + |
| 17 | +## 1.2. 模型压缩与稀疏化 |
| 18 | + |
| 19 | +## 1.3. 稀疏性 |
| 20 | +1. 为什么会有稀疏性? |
| 21 | +数据的高度结构化带来稀疏性 |
| 22 | + |
| 23 | +稀疏表示的本质:用尽可能少的资源表示尽可能多的知识,这种表示还能带来一个附加的好处,即计算速度快。 |
| 24 | + |
| 25 | +## 1.4. 神经网络的稀疏性 |
| 26 | +- 静态稀疏性 |
| 27 | + 1. 权重 |
| 28 | +- 动态稀疏性 |
| 29 | + 1. 激活函数 |
| 30 | + 2. 梯度 |
| 31 | + |
| 32 | + |
| 33 | + |
| 34 | + |
| 35 | +深度神经网络一般有较多的参数冗余,神经网络的压缩策略包括: |
| 36 | +1. 剪枝(Pruning) |
| 37 | +2. 量化(Quantization) |
| 38 | +3. 知识蒸馏(Knowledge distillation) |
| 39 | +4. 低秩分解(Low-rank factorization) |
| 40 | +...等 |
| 41 | + |
| 42 | + |
| 43 | +上述方法从模型角度分类: |
| 44 | +1. **压缩已有的网络**,包含:张量分解,模型剪枝,模型量化;(针对既有模型) |
| 45 | +2. **构建新的小型网络**,包含:知识蒸馏,紧凑网络设计;(针对新模型) |
| 46 | + |
| 47 | + |
| 48 | + |
| 49 | +# 2. 剪枝 |
| 50 | + |
| 51 | +剪枝是将训练好的模型中的允余参数去掉,达到减小模型参数量和计算量的目的。 |
| 52 | + |
| 53 | +剪枝的各种方法里,有一个非常常见的套路是三步走: |
| 54 | +$$训练-剪枝-微调$$ |
| 55 | + |
| 56 | +微调这一步隐含了一个假设,就是完整结构的大网络训练出的参数,对最终结果是有贡献的。这 |
| 57 | + |
| 58 | + |
| 59 | + |
| 60 | +在众多剪枝方法中,可以根据被裁剪的参数是否具有结构化的信息分为两类 |
| 61 | +1. 非结构化(细粒度)剪枝 |
| 62 | +2. 结构化(粗颗粒)剪枝 |
| 63 | + |
| 64 | +## 2.1. 非结构化剪枝 |
| 65 | + |
| 66 | +非结构化剪枝通常是连接级、细粒度的剪枝方法,精度相对较高,但是依赖于特定的算法库或者硬件平台的支持,如Deep Compression,Sparse-Winograd。 |
| 67 | + |
| 68 | + |
| 69 | +细粒度剪枝主要用于**压缩模型的大小**,比较有名的是韩松在论文【Deep Compression:Compressing Deep NeuralNetworks with Pruning, Trained Quantization and Huffman Coding】中提出的方法,主要包含剪枝、量化和哈弗曼编码三个步骤。 |
| 70 | + |
| 71 | +其具体的思想是认为网络中权值越靠近 0 的神经元对网络的贡献越小,剪枝的过程就是对每一层神经元的权重按照绝对值排序,按一定的比例裁剪掉最小的一部分,使得这些神经元不激活,为了保证剪枝后网络的精度损失尽量小,每次裁剪后都会对保留的非零权重进行 fine-tuning,最终能将模型大小减小 9~13 倍。 |
| 72 | + |
| 73 | +为了进一步压缩模型大小,对于剪枝后稀疏的神经元,通过量化编码,将连续的权值离散化,从而用更少比特数来存储浮点权值,如图 8 所示。最后再通过霍夫曼编码进一步压缩模型大小,最终可以在不损失精度的情况下将模型大小压缩 35 到 49 倍。 |
| 74 | + |
| 75 | +细粒度剪枝虽然能达到较高的压缩比,但稀疏的权值没有结构化的信息,如果不依赖特定预测库或硬件的优化,模型在实际运行中并不能加速,并且占用的内存也和未压缩前一样。 |
| 76 | + |
| 77 | + |
| 78 | +非结构化剪枝中的单个weight |
| 79 | + |
| 80 | + |
| 81 | +所以**细粒度的剪枝方法目前使用的相对比较少** |
| 82 | + |
| 83 | + |
| 84 | +## 2.2. 结构化剪枝 |
| 85 | + |
| 86 | +相比细粒度剪枝随机地裁剪掉网络中的若干的神经元,结构化剪枝**以一定的结构为单位进行剪枝**。 |
| 87 | + |
| 88 | +### 2.2.1. group 级别剪枝 |
| 89 | +group 级别剪枝是指对每一层的 filter 设置相同的稀疏模式(即图中每个立方体都删去相同位置的小方块),变成结构相同的稀疏矩阵 |
| 90 | + |
| 91 | + |
| 92 | +### 2.2.2. channel 级别剪枝 |
| 93 | + |
| 94 | +剪枝方法 依据 |
| 95 | +随机裁剪 随机 |
| 96 | +裁剪向量 计算二范数大小 |
| 97 | +裁剪核 对核进行裁剪 |
| 98 | +裁剪组 针对固定组的剪 |
| 99 | +裁剪通道 正常情况下用这个 |
| 100 | + |
| 101 | + |
| 102 | +如裁剪掉卷积层中若干filter,裁剪后的模型相比原始模型,只是 channel 数量减小,不需要额外的预测库支持就能达到加速的目的,因此结构化剪枝是目前使用较多的剪枝方案。 |
| 103 | + |
| 104 | +filter级或者layer级、粗粒度的剪枝方法,精度相对降低,但是剪枝策略更为有效,不需要特定算法库或者硬件平台的支持,能够直接在成熟深度学习框架上运行 |
| 105 | + |
| 106 | + |
| 107 | +> 具体要裁剪那些 filter? |
| 108 | +
|
| 109 | +在剪枝的过程中,如何确定每层的最优剪枝比例和具体要裁剪的 filter,来达到整个模型的最优压缩比是该方法中要解决的问题? |
| 110 | + |
| 111 | +对于选择哪些 filter 进行裁剪,常规的方案和细粒度剪枝类似,对不同 filter 的参数计算了 l1_norm,选择值较小的 filter 进行裁剪。 |
| 112 | + |
| 113 | +对于每层裁剪的比例,常规的方法是网络中所有层使用同样的比例,没有考虑到模型中不同层参数允余程度的差异性。 |
| 114 | + |
| 115 | +论文【Pruning Filters for Efficient ConvNets】提出了一种基于敏感度的剪枝策略,通过不同层对剪枝的敏感度来决定裁剪比例,每层敏感度的计算方法是使用不同裁剪比例对该层进行剪枝,评估剪枝后模型在验证集上的精度损失大小,对于剪枝比例越大,但精度损失越小的层,认为其敏感度越低,可以进行较大比例的裁剪。 |
| 116 | + |
| 117 | +由于每次剪枝完在验证集上进行评估的开销比较大,该方法在计算敏感度时每次只对其中的一层进行剪枝,没有考虑到不同层之间的相关性,所以实际的敏感度并不是非常准确。 |
| 118 | + |
| 119 | + |
| 120 | +# 3. 量化 |
| 121 | + |
| 122 | +量化(低比特运算)是指将神经网络中 32 位的全精度数据处理成 8 位或 16 位的定点数,同时结合硬件指定的乘法规则,就可以实现低内存带宽、低功耗、低计算资源占用以及低模型存储需求。 |
| 123 | + |
| 124 | +很多嵌入式芯片中都设计有各种位宽的乘法器,使得量化后等。 |
| 125 | + |
| 126 | +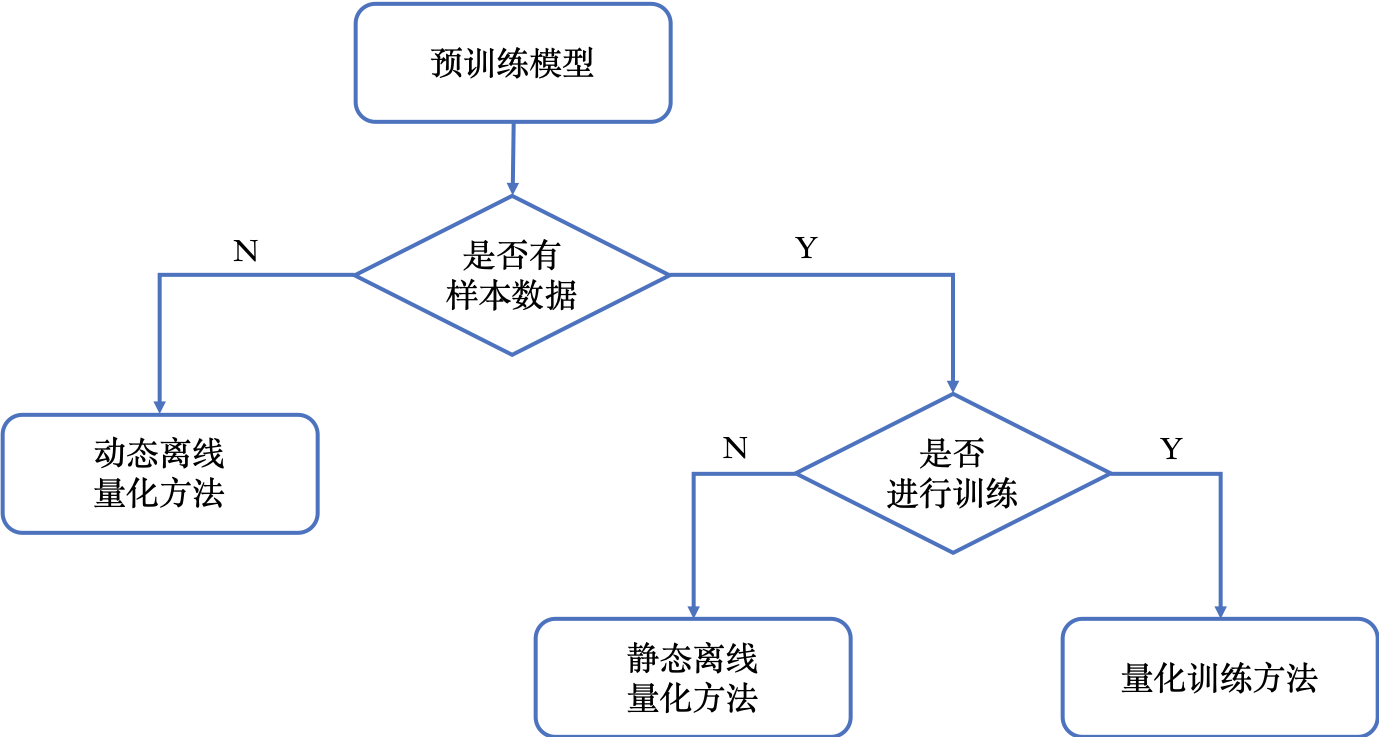 |
| 127 | + |
| 128 | + |
| 129 | + |
| 130 | + |
| 131 | +精度(Low precision)可能是最通用的概念。 |
| 132 | + |
| 133 | +常规精度:FP32(单精度32位浮点数)一般使用FP32存储模型权重; |
| 134 | +低精度:INT8;也有表示FP16(半精度16位)、INT8(8位的定点整数)等等数值格式,目前低精度往往指代INT8。 |
| 135 | +混合精度(Mixed precision)在精度中使用FP32和FP16。 |
| 136 | + |
| 137 | +FP16减少了一般的内存大小,但有些参数或者操作符必须采用FP32的格式才可以保持准确度。 |
| 138 | + |
| 139 | +**量化一般指INT8,将FP32类型转换为INT8类型,在损失少量精度的情况下,我们可以获得接近四倍的网络模型加速**。 |
| 140 | + |
| 141 | + |
| 142 | + |
| 143 | +为了解决存储和带宽的开销需求,获得更低的能耗和占用面积,同时获得更快的计算速度。 |
| 144 | +尚可接受的精度损失。即量化相当于对模型权重引入噪声,所幸CNN本身对噪声不敏感(在模型训练过程中,模拟量化所引入的权重加噪还有利于防止过拟合),在合适的比特数下量化后的模型并不会带来很严重的精度损失。按照gluoncv提供的报告,经过int8量化之后,ResNet50_v1和MobileNet1.0 _v1在ILSVRC2012数据集上的准确率仅分别从77.36%、73.28%下降为76.86%、72.85%。 |
| 145 | +根据存储一个权重元素所需要的的位数还可以有以下的方法: |
| 146 | +神经网络 方法 |
| 147 | +二值神经网络 在运行时权重和激活只取两种值(例如+1,-1)的神经网络,以及在训练师计算参数的梯度 |
| 148 | +三元权重网络 权重约束为+1,0,-1的神经网络 |
| 149 | +XNOR网络 过滤器和卷积层的输入是二进制的。XNOR网络主要视同二进制运算来近似卷积 |
| 150 | +理论是一回事,实践又是一回事,如果一种技术方法难以推广到通用场景,泽需要进行大量的额外支持。花里胡哨的研究往往是过于棘手或前提假设过于强,以至于无法引入工业界。 |
| 151 | +工业界最终选择是INT8量化——FP32在推理(inference)期间被INT8取代,训练仍然是FP32。TensorRT,TensorFlow,PyTorch.MxNet和其他许多深度学习软件都已经启用(或正在启用)量化。 |
| 152 | + |
| 153 | +通常可以根据FP32和INT8的转换机制来对解决方案进行分类。一些框架简单地引入了Quantize和Dequantize层,当从卷积或全链接层送入或者取出时,它将FP32转换为INT8或相反。在这种情况下,模型本身的输入/输出采用FP32格式。深度学习框架加载模型,重写网络以插入Quantize和Dequantize层,并且将权重转换为INT8格式。 |
| 154 | + |
| 155 | + |
| 156 | +## 3.1. 训练后量化(离线量化) |
| 157 | +离线量化又称为训练后量化,仅需要使用少量校准数据,确定最佳的量化参数降低量化误差。这种方法需要的数据量较少,但量化模型精度相比在线量化稍逊。 |
| 158 | +#### 3.1.0.1. 动态图 |
| 159 | +在推理过程中,动态统计激活的量化参数 |
| 160 | +#### 3.1.0.2. 静态图 |
| 161 | +推理过程中,对不同的输入,采用相同的从训练数据中统计得到的量化参数。 |
| 162 | +## 3.2. 量化训练 |
| 163 | +量化训练要解决的问题是将FP32浮点数量化成INT8整数进行存储和计算,通过在训练中建模量化对模型的影响,降低量化误差。 |
| 164 | + |
| 165 | + |
| 166 | + |
| 167 | +# 4. 知识蒸馏 |
| 168 | + |
| 169 | +一般情况下,模型参数量越多,结构越复杂,其性能越好,但参数也越允余,运算量和资源消耗也越大;知识蒸馏是将复杂网络中的有用信息提取出来,迁移到一个更小的网络中去,以达到模型压缩的效果。 |
| 170 | + |
| 171 | + |
| 172 | +知识蒸馏是指使用教师模型(teacher model)去指导学生模型(student model)学习特定任务,保证小模型在参数量不变的情况下,得到比较大的性能提升,甚至获得与大模型相似的精度指标 |
| 173 | + |
| 174 | + |
| 175 | + |
| 176 | + |
| 177 | +# 5. 低秩近似 |
| 178 | +对于二维矩阵运算来说SVD奇异值分解是非常好的简化方法,对于高维矩阵的运算往往会涉及到 Tensor分解方法,主要是CP分解、Tucker分解、Tensor Train分解和Block Term分解等工作。但现在低秩近似不再流行的一个重要原因是现在越来越多网络中采用1×1的卷积,而这种小的卷积使用矩阵分解的方法很难实现网络加速和压缩。而且在大型网络上低秩近似的表现不太好。 |
0 commit comments