# GitHub • # Join Discord Community • # Discussion Forum #
 '
def display_image(image_path, width=100):
if isinstance(image_path, str):
return resize_and_encode_image(image_path, width)
else:
return ''
outliers_df['filename_outlier_preview'] = outliers_df['filename_outlier'].apply(lambda x: display_image(x, width=100))
outliers_df['filename_nearest_preview'] = outliers_df['filename_nearest'].apply(lambda x: display_image(x, width=100))
display(outliers_df.style)
# Now we can export the results to a CSV file for further analysis and correction of labels.
# In[49]:
outliers_df.drop(columns=['filename_outlier_preview', 'filename_nearest_preview']).to_csv('outliers.csv', index=False)
# ## Interactive Exploration
# In addition to the static visualizations presented above, fastdup also offers interactive exploration of the dataset.
#
# To explore the dataset and issues interactively in a browser, run:
# In[ ]:
fd.explore()
# > 🗒 **Note** - This currently requires you to sign-up (for free) to view the interactive exploration. Alternatively, you can visualize fastdup in a non-interactive way using fastdup's built in galleries shown in the upcoming cells.
#
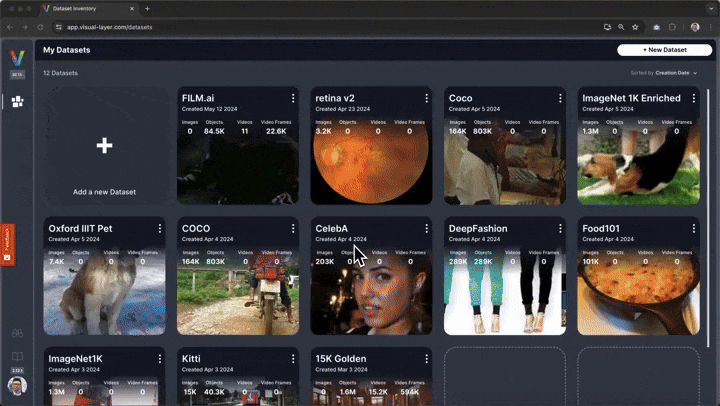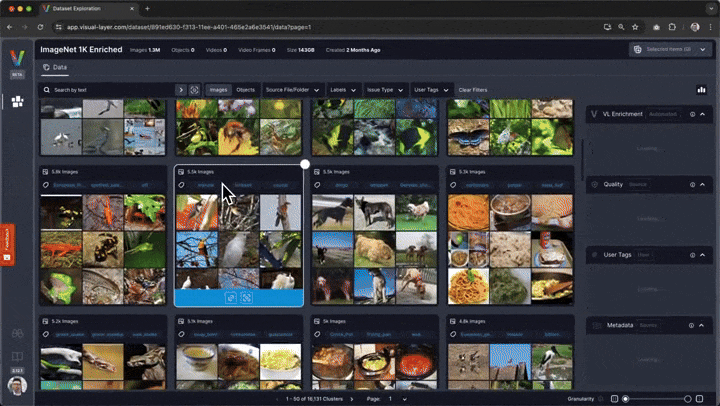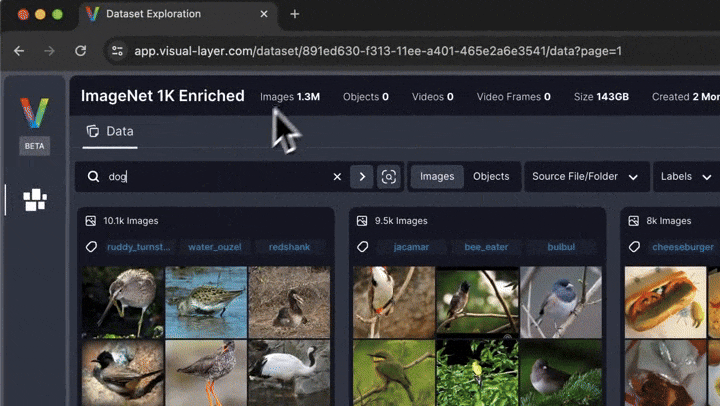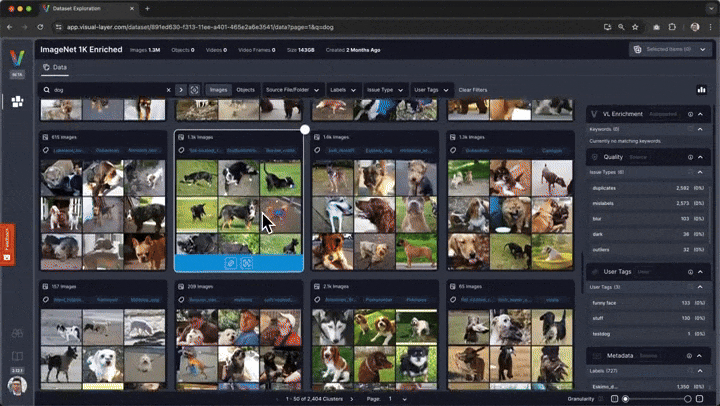
# You'll be presented with a web interface that lets you conveniently view, filter, and curate your dataset in a web interface.
#
#
# 
# ## Wrap Up
#
# That's a wrap! In this notebook, we showed how to get mislabels from a labeled dataset.
#
#
# Next, feel free to check out other tutorials -
#
# + ⚡ [**Quickstart**](https://nbviewer.org/github/visual-layer/fastdup/blob/main/examples/quick-dataset-analysis.ipynb): Learn how to install fastdup, load a dataset and analyze it for potential issues such as duplicates/near-duplicates, broken images, outliers, dark/bright/blurry images, and view visually similar image clusters. If you're new, start here!
# + 🧹 [**Clean Image Folder**](https://nbviewer.org/github/visual-layer/fastdup/blob/main/examples/cleaning-image-dataset.ipynb): Learn how to analyze and clean a folder of images from potential issues and export a list of problematic files for further action. If you have an unorganized folder of images, this is a good place to start.
# + 🖼 [**Analyze Image Classification Dataset**](https://nbviewer.org/github/visual-layer/fastdup/blob/main/examples/analyzing-image-classification-dataset.ipynb): Learn how to load a labeled image classification dataset and analyze for potential issues. If you have labeled ImageNet-style folder structure, have a go!
# + 🎁 [**Analyze Object Detection Dataset**](https://nbviewer.org/github/visual-layer/fastdup/blob/main/examples/analyzing-object-detection-dataset.ipynb): Learn how to load bounding box annotations for object detection and analyze for potential issues. If you have a COCO-style labeled object detection dataset, give this example a try.
#
# As usual, feedback is welcome! Questions? Drop by our [Slack channel](https://visualdatabase.slack.com/join/shared_invite/zt-19jaydbjn-lNDEDkgvSI1QwbTXSY6dlA#/shared-invite/email) or open an issue on [GitHub](https://github.com/visual-layer/fastdup/issues).
#
#
'
def display_image(image_path, width=100):
if isinstance(image_path, str):
return resize_and_encode_image(image_path, width)
else:
return ''
outliers_df['filename_outlier_preview'] = outliers_df['filename_outlier'].apply(lambda x: display_image(x, width=100))
outliers_df['filename_nearest_preview'] = outliers_df['filename_nearest'].apply(lambda x: display_image(x, width=100))
display(outliers_df.style)
# Now we can export the results to a CSV file for further analysis and correction of labels.
# In[49]:
outliers_df.drop(columns=['filename_outlier_preview', 'filename_nearest_preview']).to_csv('outliers.csv', index=False)
# ## Interactive Exploration
# In addition to the static visualizations presented above, fastdup also offers interactive exploration of the dataset.
#
# To explore the dataset and issues interactively in a browser, run:
# In[ ]:
fd.explore()
# > 🗒 **Note** - This currently requires you to sign-up (for free) to view the interactive exploration. Alternatively, you can visualize fastdup in a non-interactive way using fastdup's built in galleries shown in the upcoming cells.
#
# You'll be presented with a web interface that lets you conveniently view, filter, and curate your dataset in a web interface.
#
#
# 
# ## Wrap Up
#
# That's a wrap! In this notebook, we showed how to get mislabels from a labeled dataset.
#
#
# Next, feel free to check out other tutorials -
#
# + ⚡ [**Quickstart**](https://nbviewer.org/github/visual-layer/fastdup/blob/main/examples/quick-dataset-analysis.ipynb): Learn how to install fastdup, load a dataset and analyze it for potential issues such as duplicates/near-duplicates, broken images, outliers, dark/bright/blurry images, and view visually similar image clusters. If you're new, start here!
# + 🧹 [**Clean Image Folder**](https://nbviewer.org/github/visual-layer/fastdup/blob/main/examples/cleaning-image-dataset.ipynb): Learn how to analyze and clean a folder of images from potential issues and export a list of problematic files for further action. If you have an unorganized folder of images, this is a good place to start.
# + 🖼 [**Analyze Image Classification Dataset**](https://nbviewer.org/github/visual-layer/fastdup/blob/main/examples/analyzing-image-classification-dataset.ipynb): Learn how to load a labeled image classification dataset and analyze for potential issues. If you have labeled ImageNet-style folder structure, have a go!
# + 🎁 [**Analyze Object Detection Dataset**](https://nbviewer.org/github/visual-layer/fastdup/blob/main/examples/analyzing-object-detection-dataset.ipynb): Learn how to load bounding box annotations for object detection and analyze for potential issues. If you have a COCO-style labeled object detection dataset, give this example a try.
#
# As usual, feedback is welcome! Questions? Drop by our [Slack channel](https://visualdatabase.slack.com/join/shared_invite/zt-19jaydbjn-lNDEDkgvSI1QwbTXSY6dlA#/shared-invite/email) or open an issue on [GitHub](https://github.com/visual-layer/fastdup/issues).
#
# 





