9082 educate users on mat mul precision #9103
Conversation
…on-mat-mul-precision
|
PDF of doc is here |
…on-mat-mul-precision
…on-mat-mul-precision
This reverts commit 02a5069.
…on-mat-mul-precision
| # | | ||
| # |  | ||
|
|
||
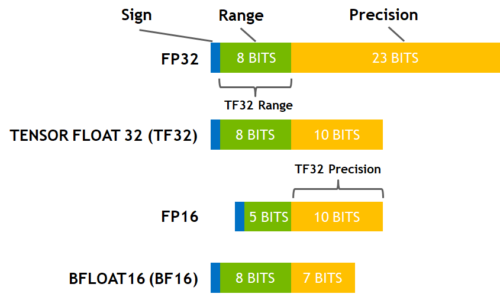
| # | ## Higher precision math on lower precision hardware |
There was a problem hiding this comment.
Perhaps we can just point readers to BFloat16: The secret to high peformance on Cloud TPUs instead of duplicating that content here.
There was a problem hiding this comment.
If you'd rather keep this section, let me know and I can clean it up. My preference would be to use the existing documentation.
There was a problem hiding this comment.
that doc doesn't share the math of how the 3 and 6 pass methods work, and we have had customer questions, so I think it's important we keep this description.
This reverts commit 6e3fdf9.
…on-mat-mul-precision
…hub.com/pytorch/xla into 9082-educate-users-on-mat-mul-precision
| # | the differences between these three settings. | ||
| # | | ||
| # | Warning: Although this notebook demonstrates different precision settings, | ||
| # | it is recommended to only set the precision once at the beginning of your |
There was a problem hiding this comment.
Not sure if it's already done; does it makes sense to throw a "hard error" when the user sets the precision twice?
There was a problem hiding this comment.
It's a good question and I'm not sure. If I was pretty sure mat_mul_precision was flakey, I'd say, definitely yes. But I am also curious if the error is not really in the platform, but rather, in the testing harness. It seems weird to me that I can set matmul precision dynamically in scripts and interactive python interpreters... (see PR 9083)... but it fails the unit test. I really don't get it.
There was a problem hiding this comment.
Ok, I know why. Looks like our compilation caching is not sound.
I ran your test a bunch of times with different levels of matmul precision. Then I printed xm.metrics_report() and it only reported 1 compilation event. I think we need at least 3 compilation events if there are 3 different precision levels.
In contrast, JAX maintains an extensive context of ambient settings that will impact compilation results: https://github.com/jax-ml/jax/blob/35e2657be8308917c7fa407be5a0b53192134890/jax/_src/config.py#L230. Whenever any of those things change, JAX will recompile.
I think the reasonable thing here is to:
- Print some warning when the precision level is changed, warning the user that existing cached graphs may nullify their precision level change. If possible, we could maybe only print this warning if the are cached graphs.
- Someone should fix this in some follow-up.
As a corollary, probably we should advise users that they better change the precision once at the start of their script.
There was a problem hiding this comment.
Thanks for this analysis! I suspected there was global state (because runtime didn't triple) but didn't know the tools you know to dig deeper. I couldn't bisect it between the python -m unittest runner and something in libtpu.
Is there a deeper fix here for which I can file an issue? E.g. can we do what Jax does and force a recompile when this ambient setting is changed? Broadly speaking, being more stringent about what constitutes a cache hit?
Either way, the note to only set this setting once is in this guide, and I'll add it to the doc string as well. I'll look into a warning as well if that's idiomatic to PyTorch.
There was a problem hiding this comment.
Is there a deeper fix here for which I can file an issue? E.g. can we do what Jax does and force a recompile when this ambient setting is changed? Broadly speaking, being more stringent about what constitutes a cache hit?
Absolutely. I'm only familiar with how JAX does it. But I could imagine a similar kind of lazy_tensor_trace_context() for PyTorch/XLA, and whatever dictionary we're currently inserting the cached compilation result into, we'll need to hash-combine the dict key with this trace context.
There was a problem hiding this comment.
It's probably a good idea to audit the JAX list and see if any other items apply to ptxla as well; not just the matmul precision
There was a problem hiding this comment.
do we have the ability to force a cache flush? That would provide a workaround.
Adds runnable tutorial to teach users about mat mul precision.
Also includes new manual build instructions for runnable tutorials.